
记录一次生产数据库紧急恢复经历
事情经过
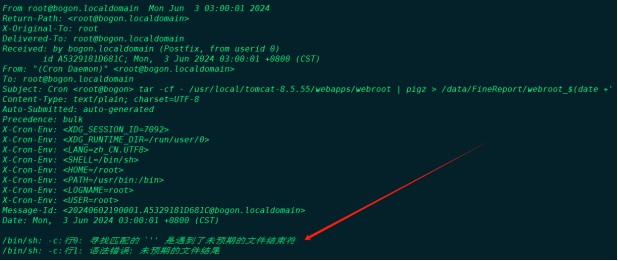
前天晚上(2024年3月31日)20点21分,钉钉突然报警,一看是任务调度平台海豚挂了一个节点,因为是集群部署有三个节点,想着挂一个也不影响,但快10点的时候突然又崩出大量报警信息,一看同步到StarRocks的任务全部报错,这个问题明显就严重很多,自从StarRocks迁移到公司集群后,已经稳定运行了七个多月,从来没有发生过这种情况。
海豚集群钉钉报警截图:

StarRocks同步任务钉钉报警截图:

StarRocks报错日志截图:
Linux后台查看StarRocks集群进程:

**结论:**这里基本确定,StarRocks集群225和226两台节点都挂了。
处理方式
起初,我尝试使用常规的方式,重启三台StarRocks节点的FE和BE进程,但225和226两台节点FE启不起来,起来秒挂,于是紧急联系了线上技术支持。

于是,在线上技术的指导下,我按照文档,先将三天节点的元数据进行备份,然后找出最新的元数据节点,再以最新的这台节点作为 LEADER 节点,将另外两台节点踢出集群,并清空这两台节点元数据,然后重新将这两台节点再加进集群。
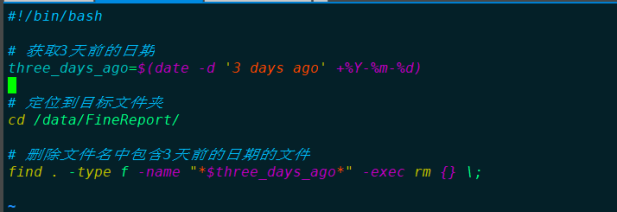
步骤一:寻找元数据最新的FE节点
需要先备份所有 FE 节点的元数据路径。该路径存储在 ${STARROCKS_HOME}/fe/meta 下。
然后执行以下操作获取 lastVLSN,该值越大则该节点元数据越新。jar包路径:/opt/soft/StarRocks-2.5.7/fe/lib
java -jar lib/starrocks-bdb-je-18.3.16.jar DbPrintLog -h meta/bdb/ -vd |
步骤二:确认恢复节点角色
进入元数据最新的节点的 image 目录查看 role 文件,确认当前节点的角色。路径为 ${STARROCKS_HOME}/fe/meta/image。推荐选择FOLLOWER节点进行恢复。
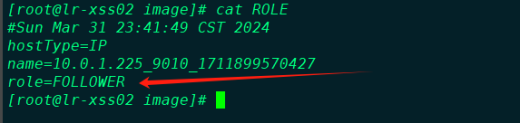
步骤三:基于FOLLOWER节点进行恢复
-
在当前节点的
fe.conf中添加以下配置。metadata_failure_recovery = true
-
启动当前 FE 节点。
sh bin/start_fe.sh --daemon
-
启动完成后,通过 MySQL 连接至当前 FE节点,执行查询导入操作,检查集群是否能够正常访问;如果无法正常访问,您需要查看 FE 节点的启动日志,排查问题后重新启动 FE 节点。
-
确认启动成功后,连接StarRocks客户端,检查当前 FE 节点角色。
# 连接客户端
mysql -hhost -P9030 -uxxx -pxxx
# 查看FE状态
show frontends;
# 查看FE状态(格式化表格)
show proc '/frontends'\G; -
【重要】将当前节点
fe.conf中的metadata_failure_recovery=true配置项删除,或者设置为false,然后重启当前 FE 节点。
步骤四:重新部署集群
在得到了一个存活的 FOLLOWER 角色的 LEADER 后,需要将之前的其他的 FE 从元数据删除。
ALTER SYSTEM DROP FOLLOWER; |
然后您需要将恢复节点的 /fe/meta/备份,然后清空该目录。
rm -rf meta/* |
最后在224和225两台节点执行以下命令,加入到新集群。
alter system add follower 10.0.1.226:9010 |
客户端查看最终的三台FE状态,显示已经可以了,StarRocks元数据恢复完毕,新集群启动成功。

异常原因排查
通过初步排查,显示节点225和226这两台虚拟机所在的服务器在2023年3月31日晚20点21分有自动故障重启的事件,具体原因不详,后续继续进行跟踪!
 微信
微信 支付宝
支付宝



