
大数据思维经典问题
大数据环境下的核心问题
- 海量数据
- 工业技术相对落后
- 硬件损坏是常态
分而治之
把一个复杂的问题按一定的“分解”方法分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的中间结果,把各部分的中间结果组成整个问题的最终结果。这也是著名的 Hadoop 中分布式存储系统 HDFS 的核心思想。
经典问题
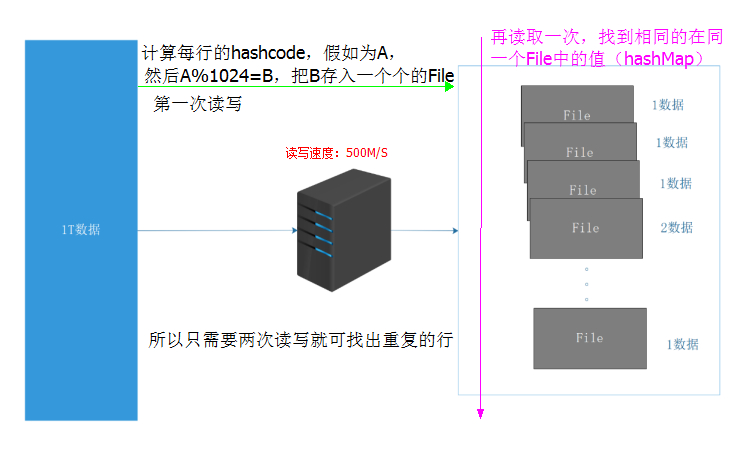
需求一:海量数据找出重复的行
已知条件: I/O 速度500M/s,服务器内存为64G,txt文件大小为1TB。
找出重复行(能不能?)
思路:
- 首先我们可以看出,文件过大,服务器不可能一次性读入,必须把文件分块或者压缩文件的大小。
- 我们可以采用哈希算法得到每行数字的 hashcode 值(因为 hashcode 是固定不变的,且内容相同的哈希值肯定是相等)。
- 这里由于需要知道行数是多少,所以我们采用 HashMap 来接收,把每行的 hashcode 作为 key ,行号作为 value ,然后对逐行的 key 除以1024(这个值可以自定义)取模,形成一个个的 File 小文件。
- 因为相同的 hashcode 取模肯定相同,也就是说落在相同的 File 文件里,这样我们再读取一次就可以找出重复的行了。这次读取我们可以直接找Key相同的值就行了。最好是第一个File文件就能找到,最坏就是在最后一个File文件中找到,这样我们按照最坏计算。
- 也就是说:==计算时间: 两次IO,2* 30分钟 = 1小时==
需求二:海量数字的全排序
已知条件: I/O 速度 500M/s,服务器内存为 64G,一个 TB 的乱序数字文件,要求进行排序。
思路:
方案一:这里也是采用分而治之的办法。
-
知道这些数字大概的范围,然后将这些数字划分成多个范围,也就是分区。注意这个分区不能超过服务器的内存,比如 64G。
-
然后就形成了,全局有序,局部无序的状态。
-
最后再分别取每个分区的小部分数据进行排序,因为这个时候每个分区文件很小,可以很快的将这些局部的数字排好序,最后把每个分区放回即可。
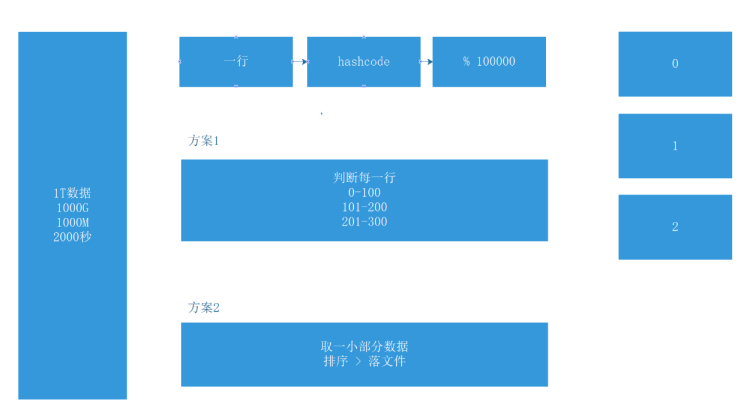
方案二:同理,用到归并算法
-
先直接分区,分为很多个小文件File,这个分区必须要小于服务器的容量,也就是说 每块容量 < 64GB,否则无法进行读写。
-
因为每个小文件因为比较小可以直接排好序。也就形成了全局无序,局部有序的状态,与方案一相反。
-
这时可以采用归并算法来进行每块的排序,使局部变得有序,最后放回即可完成。
-
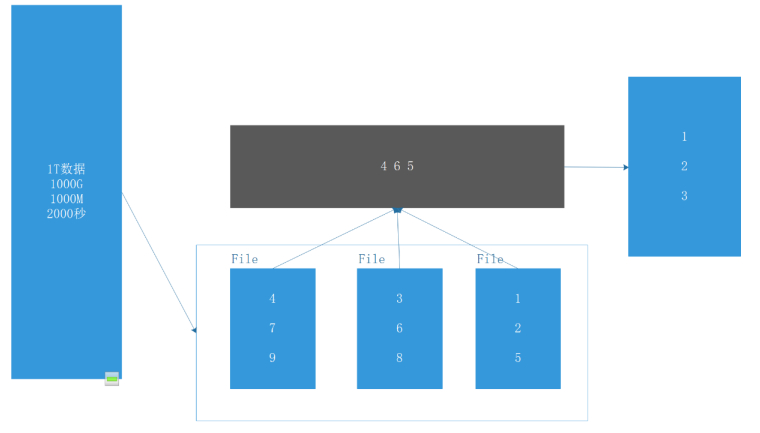
简单理解归并算法:如下图所示,因为每组数字已经是有序的,那么先拿出每组的第一个数也就是最小值,线型比较跳出最小值,比如第一次比较的是 4、3、1 挑出 1,然后后面的数接着往上补,也就是 2 上去,重新组成 4、3、2,接着又挑出 2 ,接着 5 上去,组成 4、3、5 ,挑出 3,这样循环往复,最终会使整个数排序完成。
这个算法就相当于玩拳皇 97,对打不过,下面的预选人接着上,打赢了就留下,输了就出去,一直比下去,最强最大的那个会留到最后。哈哈。。。
注:
**归并排序(MERGE-SORT)**是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
 微信
微信 支付宝
支付宝



