
分布式文件存储系统HDFS
Hadoop 分布式简介
1. Hadoop 是分布式的系统架构,是Apache基金会顶级金牌项目
注:在Apache中,凡是域名以某个项目名字作为开头的,都是Apache基金会中的顶级金牌项目。
2. Hadoop 的思想之源
来自于Google 03年发布3大论文, GFS、mapreduce、 Bigtable ;Dougcutting用Java实现)。
3. Hadoop 创始人
Hadoop作者Doug cutting,就职Yahoo期间开发了Hadoop项目,目前在Cloudera 公司从事架构工作。
2003-2004年,Google公开了部分GFS和Mapreduce思想的细节,以此为基础Doug Cutting等人用了2年业余时间实现了DFS和Mapreduce机制,一个微缩版:Nutch
Hadoop 于 2005 年秋天作为 Lucene的子项目 Nutch的一部分正式引入Apache基金会。
2006 年 3 月份,Map-Reduce分布式离线计算 和 Nutch Distributed File System (NDFS) nutch分布式文件系统分别被纳入称为 Hadoop 的项目中。
分布式文件存储系统 HDFS
HDFS 是什么?
面对的大量的数据和如何计算的难题
例如:大量【pb级以上】的网页怎么存储问题
分布式存储系统HDFS (Hadoop Distributed File System)主要解决大数据的存储问题。
HDFS的优缺点
1. 优点
(1) 分布式的特性:
-
适合大数据处理:GB 、TB 、甚至 PB 级及以上的数据
-
百万规模以上的文件数量:10K+ 节点。
-
适合批处理:移动计算而非数据(MR),数据位置暴露给计算框架
(2) 自身特性:
-
可构建在廉价机器上
-
高可靠性:通过多副本提高可靠性
-
高容错性:数据自动保存多个副本;副本丢失后,自动恢复,提供了恢复机制
2. 缺点
(1) 低延迟高数据吞吐访问问题
-
比如不支持毫秒级
-
吞吐量大但有限制于其延迟
(2) 小文件存取占用NameNode大量内存(寻道时间超过读取时间(99%))
(3) 不支持文件修改:一个文件只能有一个写入者(深入)
- 仅支持append不支持修改(其实本身是支持的,主要为了空间换时间,节约成本)
HDFS的架构
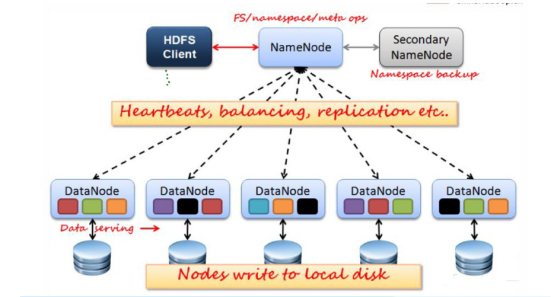
HDFS的功能模块及原理详解
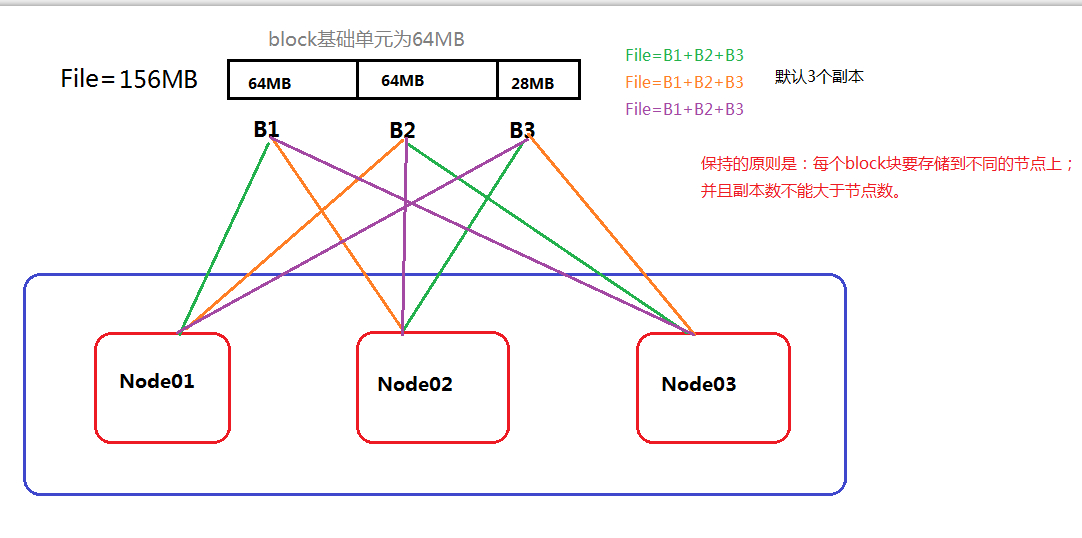
HDFS 数据存储模型(block)
1. 文件被线性切分成固定大小的数据块 block
- 通过偏移量
offset(单位:byte)标记 - 默认数据块大小为64MB (hadoop1.x),可自定义配置
- 若文件大小不到64MB ,则单独存成一个block
2. 一个文件存储方式
- 按大小被切分成若干个block ,存储到不同节点上
- 默认情况下每个block都有2个副本,共3个副本
- 副本数不大于节点数
3. Block大小和副本数通过Client端上传文件时设置,文件上传成功后副本数可以变更,Block Size大小不可变更。
NameNode(简称NN)
1. NameNode主要功能:
- 接受客户端的读/写服务。
- 接受 DateNode(DN) 汇报的 block 位置信息。
2. NameNode 保存 metadata 元信息。
metadata 基于内存存储 :不会和磁盘发生交换;
metadata元数据信息包括:
- 文件owership(归属)和 permissions(权限)
- 文件大小、时间
- Block列表[偏移量]:即一个完整文件有哪些block
- 位置信息 = Block 每个副本保存在哪个 DataNode 中(由DataNode启动时上报给 NN 因为会随时变化,不保存在磁盘)-- 动态的
3. NameNode 的 metadata 信息在启动后会加载到内存
- metadata存储到磁盘文件名为”fsimage”的镜像文件
- Block的位置信息不会保存到fsimage
- edits记录对metadata的操作日志
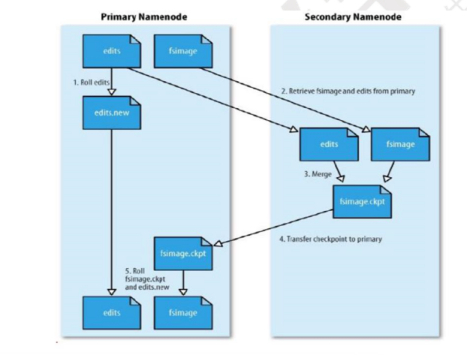
SecondaryNameNode(SNN)
1. 它的主要工作是帮助NN合并edits log文件,减少NN启动时间,它不是NN的备份(但可以做备份)。
2. SNN执行合并时间和机制
- 根据配置文件设置的时间间隔fs.checkpoint.period 默认3600秒
- 根据配置文件设置 edits log 大小 fs.checkpoint.size 规定 edits 文件的最大值默认是 64MB
3. SecondaryNameNode SNN合并流程
DataNode(DN)
– 存储数据(Block)
– 启动DN线程的时候会向 NameNode 汇报 block 位置信息
– 通过向 NN 发送心跳保持与其联系(3秒一次),如果 NN 10分钟没有收到 DN的心跳,则认为其已经 lost,并 copy 其上的 block 到其它 DN
Block的副本放置策略
1. 第一个副本:
如果是集群内提交,放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
2. 第二个副本:
放置在于第一个副本不同的机架的节点上。
3. 第三个副本:
与第二个副本相同机架的不同节点。
更多副本:随机节点
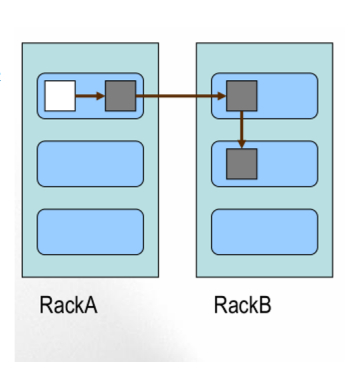
注意:空白处为客户端。
HDFS 读写流程
FileSystem是一个通用文件系统的抽象基类,可以被分布式文件系统继承,所有可能使用Hadoop文件系统的代码,都要使用这个类。- Hadoop为FileSystem这个抽象类提供了多种具体实现。
DistributedFileSystem就是FileSystem在HDFS文件系统中的具体实现。- FileSystem的
open()方法返回的是一个输入流FSDataInputStream对象,在HDFS文件系统中,具体的输入流就是DFSInputStream;FileSystem中的create()方法返回的是一个输出流FSDataOutputStream对象,在HDFS文件系统中,具体的输出流就是DFSOutputStream。
Configuration conf = new Configuration(); //环境配置 |
**备注:**创建一个Configuration对象时,其构造方法会默认加载工程项目下两个配置文件,分别是hdfs-site.xml以及core-site.xml,这两个文件中会有访问HDFS所需的参数值,主要是fs.defaultFS,指定了HDFS的地址(比如hdfs://localhost:9000),有了这个地址客户端就可以通过这个地址访问HDFS了。
1. 读文件过程
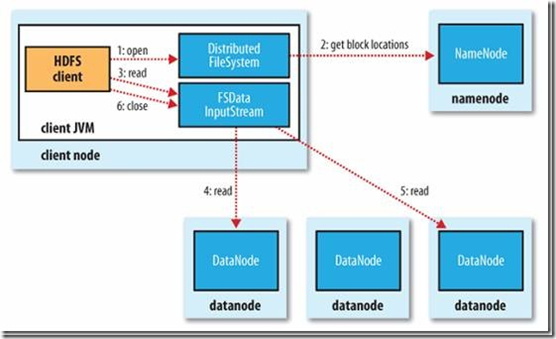
(1) 首先客户端通过基类 FileSystem 的 open( ) 方法,其实获取的是它的一个实例 DistributedFileSystem 。
(2) DistributedFileSystem 通过 **RPC协议 **调用 NameNode 来获得文件的第一批 block 的 locations 地址,(同一个 block 按照重复数会返回多个 locations,因为同一文件的 block 分布式存储在不同节点上),这些 locations 按照 hadoop 拓扑结构排序,距离客户端近的排在前面(就近原则选择)。
(3) 前两步会向客户端返回一个输入流对象 FSDataInputStream ,用于给客户端读取数据。FSDataInputStream里面会封装一个DFSInputStream对象(封装在里面看不到),DFSInputStream是专门针对HDFS的实现。DFSInputStream 可以方便的管理 datanode 和 namenode数据流。
(4) 以上完成后,客户端便会在这个输入流之上调用 read( ) 方法,DFSInputStream 最会找出距离客户端最近的datanode 并连接。数据从 datanode 源源不断的流向客户端。
(5) 如果第一个block块的数据读完了,就会关闭指向第一个block块的datanode连接,接着读取下一个block块。这些操作对客户端来说是透明的,从客户端的角度来看只是读一个持续不断的流。
(6) 如果第一批 block 都读完了, DFSInputStream 就会去 namenode 拿下一批 block 的 locations,然后继续读,如果所有的块都读完,客户端调用 close( ) 方法关闭掉所有的流。
读文件的异常情况处理
如果在读数据的时候, DFSInputStream 和 datanode 的通讯发生异常,就会尝试正在读的 block 的排序第二近的 datanode,并且会记录哪个 datanode 发生错误,剩余的 blocks 读的时候就会直接跳过该 datanode。 DFSInputStream 也会检查block 数据校验和,如果发现一个坏的 block,就会先报告到 namenode 节点,然后 DFSInputStream 在其他的 datanode上读该 block 的镜像。
RPC协议
RPC(Remote Procedure Call Protocol)——远程过程调用协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层**。**RPC使得开发包括网络分布式多程序在内的应用程序更加容易。
2. 写文件过程(流水线的复制方式)
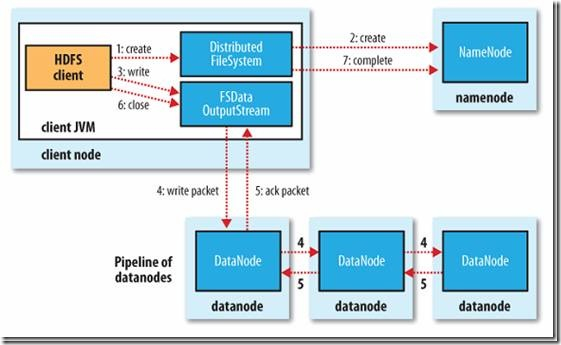
(1) 客户端通过调用基类 FileSystem 的 create() 方法,获取它的一个实例 DistributedFileSystem 。
(2) DistributedFileSystem 通过 **RPC协议 **调用 namenode,在文件系统的命名空间中创建一个新的文件,创建前, namenode 会做各种校验,比如文件是否存在,客户端有无权限去创建等。如果校验通过, namenode 就会记录下新文件,否则就会抛出 IO 异常。
(3) 前两步结束后,会返回一个输出流 FSDataOutputStream,用于客户端写数据。与读文件的时候相似,FSDataOutputStream里面又封装了一个DFSOutputStream对象。DFSOutputStream也是专门针对HDFS的实现。DFSOutputStream可以协调 namenode 和 datanode。
(4) 以上完成后,客户端调用write( )方法,DFSOutputStream会把数据分成一个个小的 packet,写入到内部队列write quene 。
(5) DataStreamer 会去处理接收 write quene,它先询问 namenode 这个新的 block最适合存储的在哪几个 datanode 里(比如重复数是3,那么就找到3个最适合的datanode),把他们排成一个管道 pipeline 输出。DataStreamer 把 packet 按队列输出到管道的第一个 datanode 中,第一个 datanode 又把 packet 输出到第二个datanode 中,以此类推。
(6) DFSOutputStream 还有一个对列叫 ack quene,也是由 packet 组成,用于等待datanode 的响应。当 pipeline 中的 datanode 都表示已经收到数据的时,ack quene 才会把对应的 packet 包移除掉。 如果在写的过程中某个 datanode 发生错误,会采取以下几步:
-
pipeline被关闭掉;
-
为了防止防止丢包。ack quene 里的 packet 会同步到 data quene 里;创建新的 pipeline 管道到其他正常 DN 上;
-
剩下的部分被写到剩下的两个正常的 datanode 中;
-
namenode 找到另外的 datanode 去创建这个块的复制。当然,这些操作对客户端来说是无感知的。
(6) 客户端完成写数据后调用close方法关闭写入流。
完全分布式搭建
完全分布式搭建
1. 环境的准备
- Linux 系统
- JDK 环境
- 准备至少3台机器(通过克隆虚拟机;配置好网络JDK 时间 hosts,保证节点间能互ping通)
- 时间同步 ( ntpdate cn.ntp.org.cn )
- ssh免秘钥登录 (两两互通免秘钥)

2. 搭建步骤
(1) 下载解压缩 Hadoop
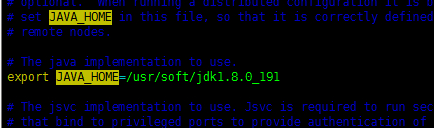
(2) 找到 hadoop 安装包下配置 etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/java/latest #跟上自己实际的 JDK 路径 |
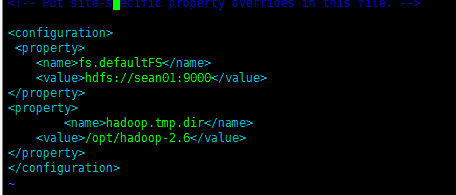
(3) 核心配置 core-site.xml (同上都在hadoop安装包的 /etc/hadoop/ 下)
fs.defaultFS 默认的服务端口 NameNode URI
hadoop.tmp.dir 是hadoop文件系统依赖的基础配置,很多路径都依赖它。如果 hdfs-site.xml 中不配置 namenode 和 datanode 的存放位置,默认就放在这个路径中。
|
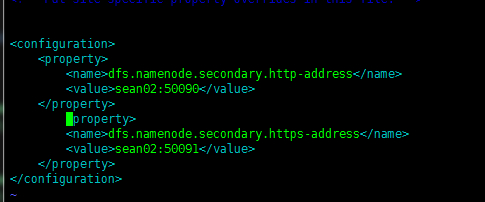
(4) HDFS 配置 hdfs-site.xml(同上都在hadoop安装包的 /etc/hadoop/ 下)
dfs.datanode.https.address https服务的端口
<configuration> |
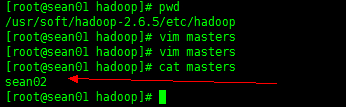
(5) Masters: master 可以做主备的 SNN
在/hadoop-2.6.5/etc/hadoop新建 masters 文件 写上 SNN 节点名: sean02
(6) Slaves: slave 干活的节点
在/home/hadoop-2.5.1/etc/hadoop/slaves 文件中填写 DN 节点名:sean01 sean02 sean03 [ 注意:每行写一个 写成3行 ]
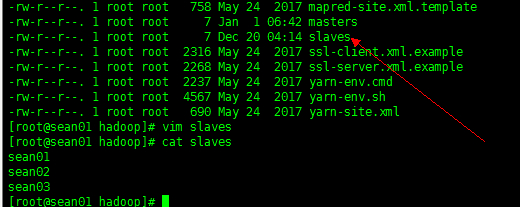
(7) 最后将配置好的 Hadoop 通过 SCP 命令发送都其他节点。
scp -r hadoop-2.6.5 sean02:/usr/soft |
scp -r hadoop-2.6.5 sean03:/usr/soft |
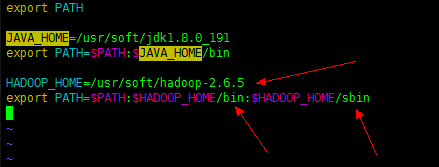
(8) 配置Hadoop的环境变量
配置局部环境变量:vi ~/.bash_profile
export HADOOP_HOME/home/hadoop-2.6.5 |
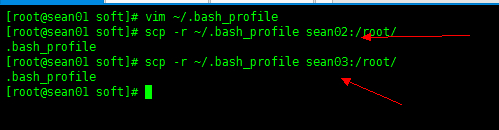
然后不要忘记把环境变量发送到另外两个节点
(9) 一定要执行一下(所有节点): source ~/.bash_profile
(10) 回到跟目录下对NN进行格式化: hdfs namenode -format
(11) 启动HDFS: start-dfs.sh

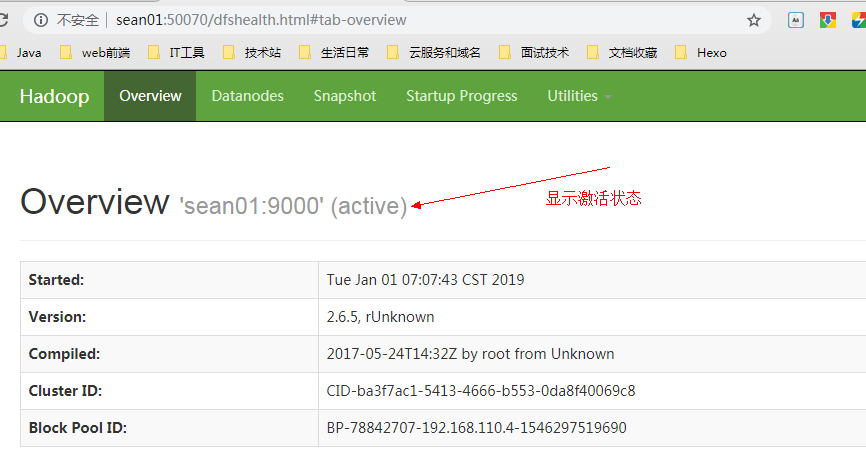
(12) 不要忘记关闭防火墙:service iptables stop
(13) 在浏览器输入 sean01:50070 出现以下界面成功(此处输入sean01的前提是windows端已经配置了hosts)
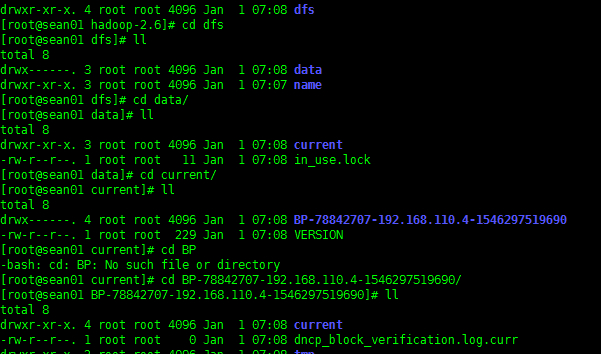
此时会发现 /opt/hadoop-2.6/dfs/ 下会多出一个 data 文件夹
里面存放的就是 DN 的数据
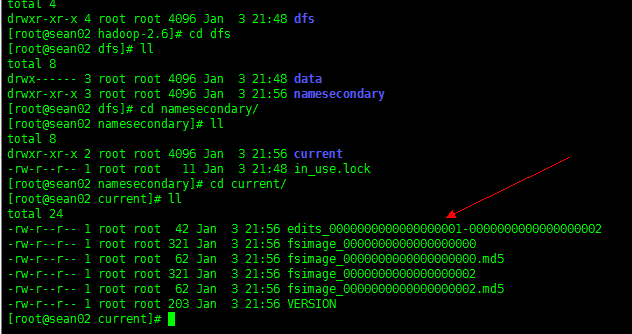
而 sean02 节点的 /opt/hadoop-2.6/dfs/namesecondary/current/ 下存放的就是元数据镜像文件和操作记录 edits
HDFS 命令
1. 常用命令
hdfs dfs -du 显示文件(夹)大小
hdfs dfs -mkdir 创建文件夹
hdfs dfs -rm -r path 删除
如果想查看其他命令,可以通过命令 hdfs dfs 直接查看相关参数即可。
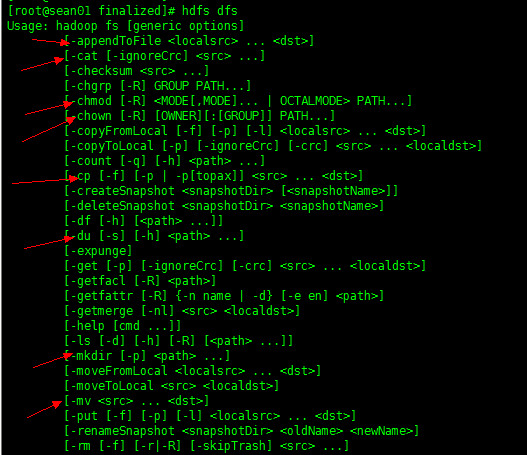
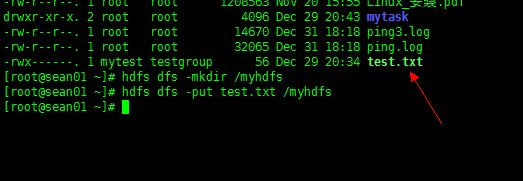
2. 举例说明
新建一个文件夹 myhdfs 到 HDFS 根目录,并且当前 root 目录下的 test.txt 文件到 myhdfs 中
然后我们来web 端查看是否成功。
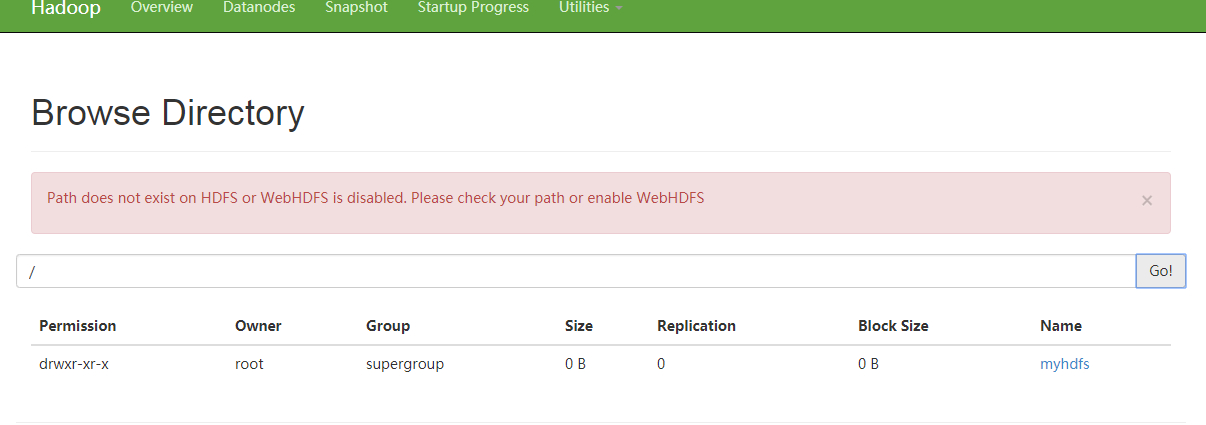
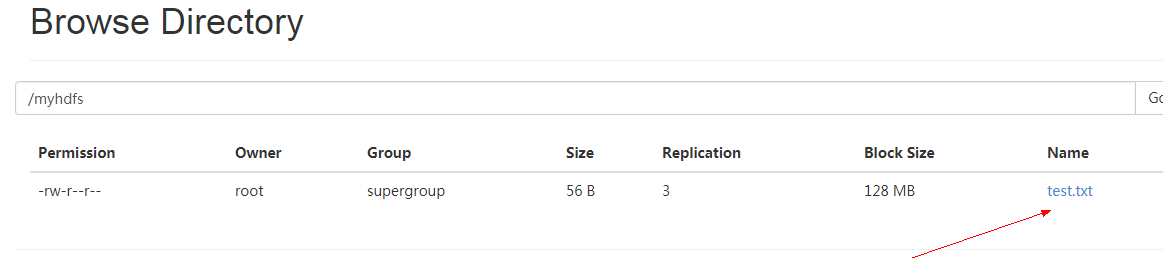
如上显示说明已经创建文件夹并且上传文件成功!
 微信
微信 支付宝
支付宝



