
Hadoop2.X
Hadoop 2.0 产生背景
根本原因:Hadoop 1.0 中 HDFS 和 MapReduce 在高可用、扩展性等方面存在问题。
1. HDFS 存在的问题
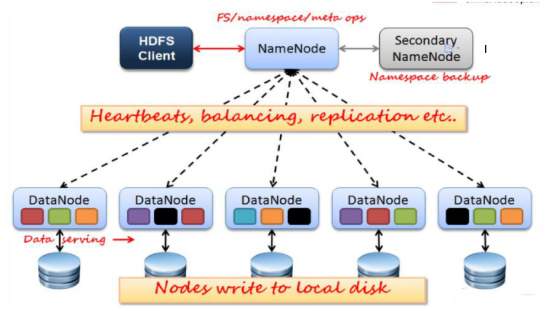
- NameNode 单点故障,难以应用于在线场景。
- NameNode 压力过大,且内存受限,影响系统扩展性
2. MapReduce 存在的问题
- JobTracker 访问压力大,影响系统扩展性。
- 难以支持除 MapReduce 之外的计算框架,比如 Spark、Storm 等。
Hadoop 2.X
1. 系统架构

Hadoop 2.x 由 HDFS、MapReduce 和 YARN 三个分支构:
- HDFS:分布式文件存储系统
- YARN:资源管理系统
- MapReduce:运行在YARN上的MR
2. 解决的问题
-
解决单点故障问题
HDFS HA:通过主备 NameNode 解决,如果主 NameNode 发生故障,则切换到备 NameNode 上。
-
解决内存受限问题
HDFS Federation(联邦机制)、HA
3. 新的变化
2.x 支持2个 NN 节点的 HA,3.0实现了 NN 一主多从。
- 水平扩展,支持多个 NameNode
- 每个 NameNode 分管一部分目录
- 所有 NameNode 共享所有 DataNode 存储资源
注意:2.x仅是架构上发生了变化,使用方式不变
HDFS 2.0 HA高可用
NameNode的HA
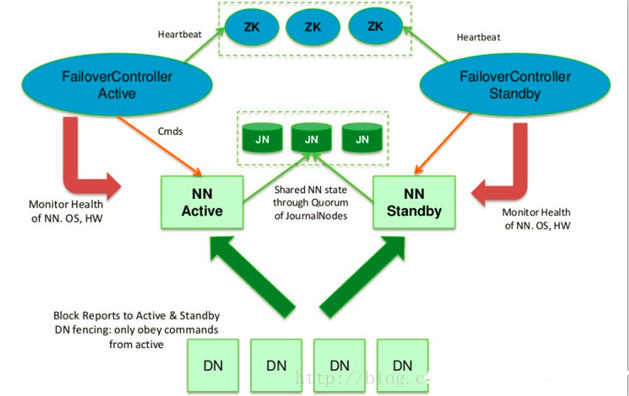
1、实现原理
配置的HA的HDFS,所有NameSpace的NameNode节点在启动加载完元数据之后都处于Standby状态,之后被手动或自动的选择一个NameNode节点作为Active节点而开始正常工作。HA的自动方式是通过在每一个NameNode的本地启动一个守护进程 ZKFailoverController 来竞争Active NameNode的,ZKFailoverController除了为本地的NameNode争取Active角色之外,还负责监控本地的NN节点当前是否正常的,一旦它发现本地的NN不正常,就会主动替当前的Active NN退出Active角色或退出Active的竞争。
2、JN (JournalNode) 实现主备 NN(NameNode) 间的数据共享
-
主备 NameNode
-
解决单点故障
主 NameNode 对外提供服务,备 NameNode 同步主 NameNode 元数据,以待切换,所有 DataNode 同时向两个 NameNode 汇报数据块信息。
-
两种切换选择
手动切换:通过命令实现主备之间的切换,可以用 HDFS 升级等场合。
自动切换:基于 Zookeeper 实现。
-
基于 **Zookeeper **自动切换方案
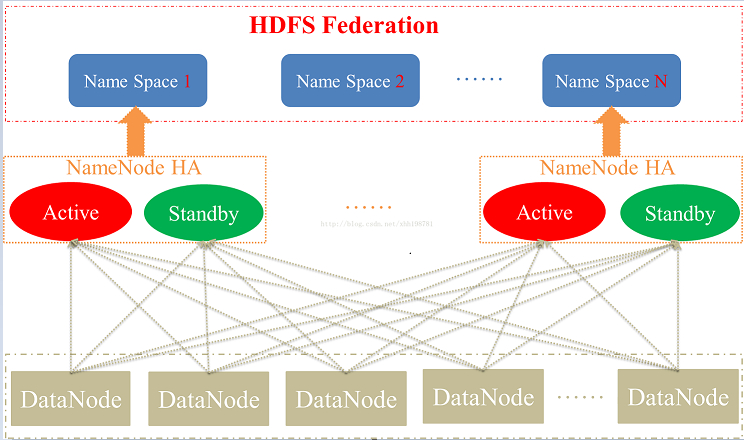
Federation联邦机制
在Hadoop2.0之前,HDFS的单NameNode设计带来诸多问题:
单点故障、内存受限,制约集群扩展性和缺乏隔离机制(不同业务使用同一个NameNode导致业务相互影响)等。为了解决这些问题,除了用基于共享存储的HA解决方案我们还可以用HDFS的Federation机制来解决这个问题。【单机namenode的瓶颈大约是在4000台集群,而后则需要使用联邦机制】
1、什么是Federation机制
Federation是指HDFS集群可使用多个独立的NameSpace(NameNode节点管理)来满足HDFS命名空间的水平扩展
这些NameNode分别管理一部分数据,且共享所有DataNode的存储资源。
NameSpace之间在逻辑上是完全相互独立的(即任意两个NameSpace可以有完全相同的文件名)。在物理上可以完全独立(每个NameNode节点管理不同的DataNode)也可以有联系(共享存储节点DataNode)。一个NameNode节点只能管理一个Namespace。
2、Federation机制解决单NameNode存在的以下几个问题
(1)HDFS集群扩展性。每个NameNode分管一部分namespace,相当于namenode是一个分布式的。
(2)性能更高效。多个NameNode同时对外提供服务,提供更高的读写吞吐率。
(3)良好的隔离性。用户可根据需要将不同业务数据交由不同NameNode管理,这样不同业务之间影响很小。
(4)Federation良好的向后兼容性,已有的单Namenode的部署配置不需要任何改变就可以继续工作。
3、Federation不足之处
HDFS Federation并没有完全解决单点故障问题。虽然namenode/namespace存在多个,但是从单个namenode/namespace看,仍然存在单点故障。因此 Federation中每个namenode配置成HA高可用集群,以便主namenode挂掉一下,用于快速恢复服务。
4、Federation架构
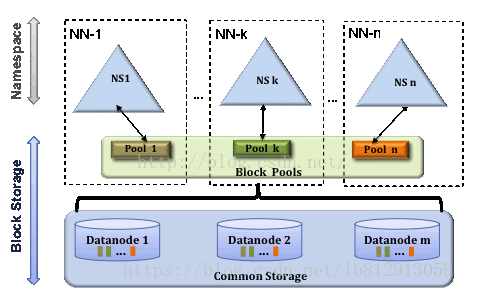
(1)为了水平扩展namenode,federation使用了多个独立的namenode/namespace。
这些namenode之间相互独立且不需要互相协调,各自分工,管理自己的区域。分布式的datanode被用作通用的数据块存储存储设备。每个datanode要向集群中所有的namenode注册,且周期性地向所有namenode发送心跳和块报告,并执行来自所有namenode的命令。
(2)每个namenode维护一个命名空间卷(namespace volume)。
由命名空间的元数据和一个数据块池组成,数据块池(block pool)包含该命名空间下文件的所有数据块。
(3)命名空间卷之间相互独立
两两之间并不互相通信,甚至其中一个namenode的失效也不会影响由其他namenode维护的命名空间的可用性。
(4)一个namespace和它的blockpool作为一个管理单·元(称为namespace volume)
数据块池不再切分,则集群中的DataNode需要注册到每个namenode,并且存储着来自多个数据块池中的数据块。当namenode/namespace被删除后,其所有datanode上对应的block pool也会被删除。集群升级时,这个管理单元也独立升级。
HDFS-2.0 HA+Federation的总体设计架构图
YARN介绍
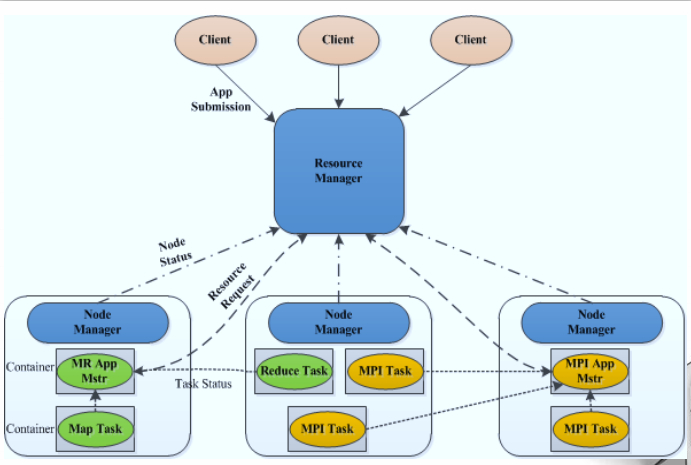
核心思想与架构
将MRv1中JobTracker的资源管理和任务调度两个功能分开,分别由ResourceManager和ApplicationMaster进程实现。
1. ResourceManager
负责整个集群的资源管理和调度。
2. ApplicationMaster
负责应用程序相关的事务,比如任务调度、任务监控和容错等。
3. YARN 的基本架构图
4. 以YARN为核心的生态系统
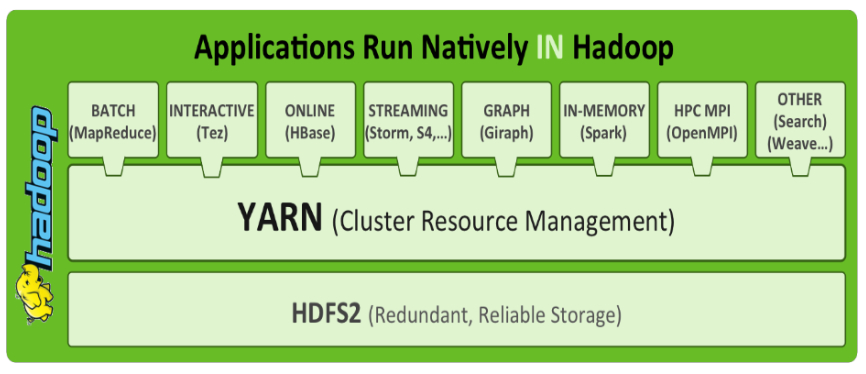
YARN 的作用
YARN的引入,使得多个计算框架可运行在一个集群中
每个应用程序对应一个 ApplicationMaster(应用程序控制-主人),目前多个计算框架可以运行在YARN上,比如 MapReduce、Spark、Storm 等。
YARN 资源管理任务调度
yarn-Client提交任务方式
1. 配置
在client节点配置中spark-env.sh添加Hadoop_HOME的配置目录即可提交yarn 任务。
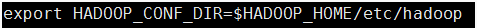
注意client只需要有Spark的安装包即可提交任务,不需要其他配置(比如slaves)!!!
2. 执行流程(重要理解)

(1) 客户端启动一个Driver进程来提交一个 Application。
(2) Driver 进程会向 RS(ResourceManager) 发送请求,启动 AM (AplicationMaster) 的资源。
(3) RS收到请求,随机选择一台 NM(NodeManager) 启动AM。这里的 NM 相当于Standalone 中的 Worker 节点。
(4) AM 启动后,会向RS请求一批 container 资源,用于启动 Executor。
(5) RS 会找到一批 NM 返回给 AM,用于启动 Executor。
(6) AM 会向 所有的 NM 发送命令启动 Executor。
(7) Executor 启动后,会反向注册给 Driver,Driver 发送 task 到 Executor,执行情况和结果返回给 Driver 端。
3. 总结
(1) Yarn-client 模式同样是适用于测试,因为 Driver 运行在本地,Driver 会与yarn 集群中的 Executor 进行大量的通信,会造成客户机网卡流量的大量增加。
(2) ApplicationMaster 的作用:
-
为当前的 Application 申请资源
-
给 NodeManager 发送消息启动 Executor。
注意:ApplicationMaster 有 launchExecutor 和申请资源的功能,并没有作业调度的功能。
yarn-Cluster提交任务方式
1. 执行流程
其实 yarn-Cluster 的提交方式跟 yarn-Client 基本相同,不同的只是 Driver 进程不在客户端启动,而是在ApplicationMaster 中,此时 AM 就相当于 Driver 端。
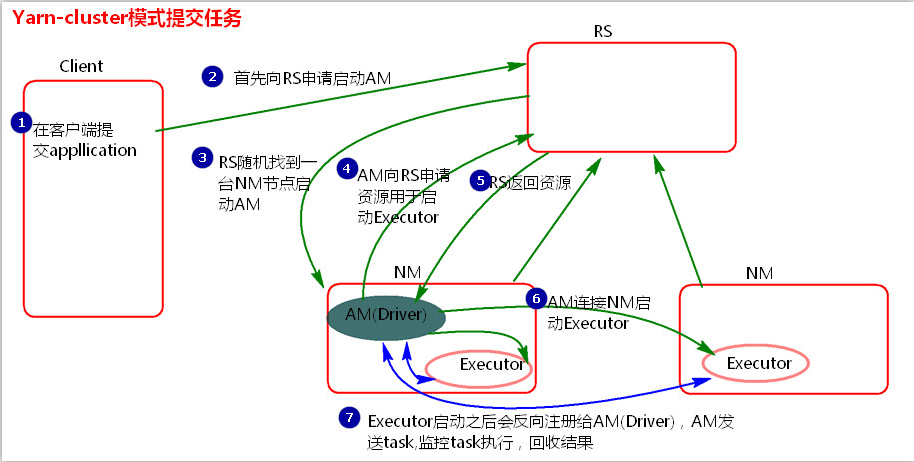
(1) 客户机提交 Application 应用程序,发送请求到 RS (ResourceManager),请求启动 AM (ApplicationMaster)。
(2) RS 收到请求后随机在一台 NM (NodeManager) 上启动 AM(相当于 Driver端)。
(3) AM 启动,**AM 发送请求到 RS,**请求一批 container 用于启动 Executor。
(4) RS 返回一批 NM 节点给 AM。
(5) AM 连接到 NM,发送请求到 NM 启动 Executor。
(6) **Executor 反向注册到 AM **所在的节点的Driver。Driver发送task到Executor。
2. 总结
(1) Yarn-Cluster主要用于生产环境中,因为Driver运行在Yarn集群中某一台nodeManager中,每次提交任务的Driver 所在的机器都是随机的**,不会产生某一台机器网卡流量激增的现象,**缺点是任务提交后不能看到日志。只能通过 yarn 查看日志。
(2) ApplicationMaster的作用:
-
为当前的Application申请资源
-
给nodemanager发送消息 启动Excutor。
-
任务调度。(这里和client模式的区别是AM具有调度能力,因为其就是Driver端,包含Driver进程)
(3) 停止集群任务命令:yarn application -kill applicationID
**自我思考:**stand-alone模式中Master发送对应的命令启动Worker上的executor进程,而yarn模式中的applimaster也是负责启动worker中的Driver进程,可见都是master负责发送消息,然后再对应的节点上启动executor进程。
MapReduce On YARN
MapReduce On YARN 是在 Hadoop2.0 版本开始构建在 MRv2 系统上。
将 MapReduce 作业直接运行在YARN上,而不是由 JobTracker 和 TaskTracker 构建的 MRv1 系统中。
1. 基本功能模块
-
**YARN:**负责资源管理和调度
-
**MRAppMaster:**负责任务切分、任务调度、任务监控和容错等
-
**MapTask/ReduceTask:**任务驱动引擎,与 MRv1 一致
2 . 每个 MapRduce 作业对应一个 MRAppMaster 任务调度
- YARN 将资源分配给 MRAppMaster
- MRAppMaster进一步将资源分配给内部的任务
3. MRAppMaster 容错
- 失败后,由 YARN 重新启动
- 任务失败后,MRAppMaster 重新申请资源
Zookeeper
ZooKeeper 是一个开源的、分布式应用程序协调服务,是 Google 的 Chubby 一个开源的实现,是 Hadoop 和 Hbase 的重要组件。
关于Zookeeper详细的原理讲解请参照 深入Zookeeper
Hadoop2.X 集群搭建
集群规划
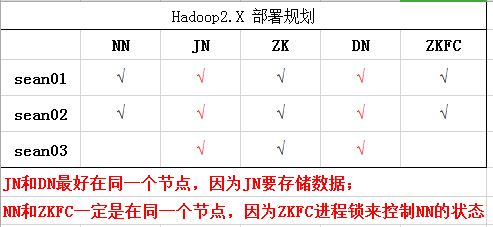
NN: NameNode
JN: JournalNode
ZK: Zookeeper
DN: DateNode
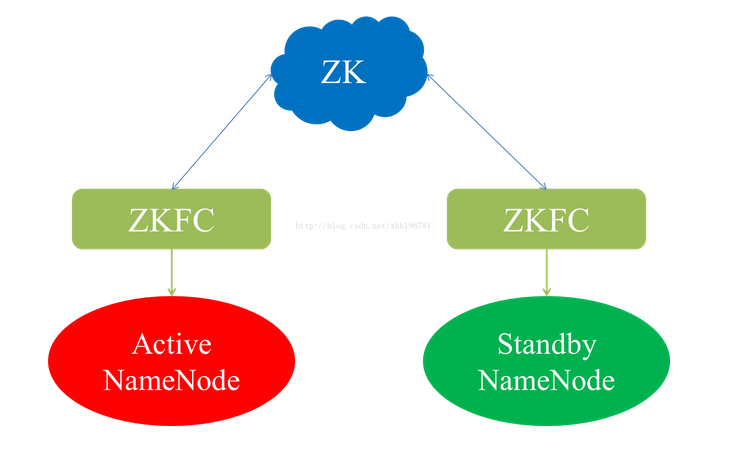
ZKFC: Zookeeper Failover Controller ==>监控 NameNode 健康状态,并向Zookeeper 注册 NameNode,NameNode 挂掉后,ZKFC 为 NameNode 竞争锁,获得 ZKFC 锁的 NameNode 变为 active。
具体搭建步骤
1、下载上传Hadoop压缩包,并配置环境变量
vim Hadoop-env.sh |
2、配置核心xml文件和hdfs文件
core-site.xml
<configuration> |
hdfs-site.xml
<configuration> |
3、准备 zookeeper
a) 三台zookeeper:sean01,sean02,sean03
b) 编辑zoo.cfg配置文件
i. 修改dataDir=/opt/zookeeper
ii. 加上下面3行
server.1=sean01:2888:3888 |
c) 在 dataDir 目录中创建一个myid的文件,文件内容分别为1,2,3
4、配置 hadoop 中的 slaves

5、发送其他节点服务器 环境变量配置
6、启动三个zookeeper(启动前一定要关闭防火墙,否则失败):
zkServer.sh start |
7、启动三个JournalNode:
hadoop-daemon.sh start journalnode |
8、在其中一个namenode上格式化:
hdfs namenode -format |
9、把刚刚格式化之后的元数据拷贝到另外一个namenode上
a) 启动刚刚格式化的 namenode : hadoop-daemon.sh start namenode
b) 在没有格式化的 namenode上执行:hdfs namenode -bootstrapStandby
c) 启动第二个namenode:hadoop-daemon.sh start namenode
10、在其中一个namenode上初始化zkfc:hdfs zkfc -formatZK
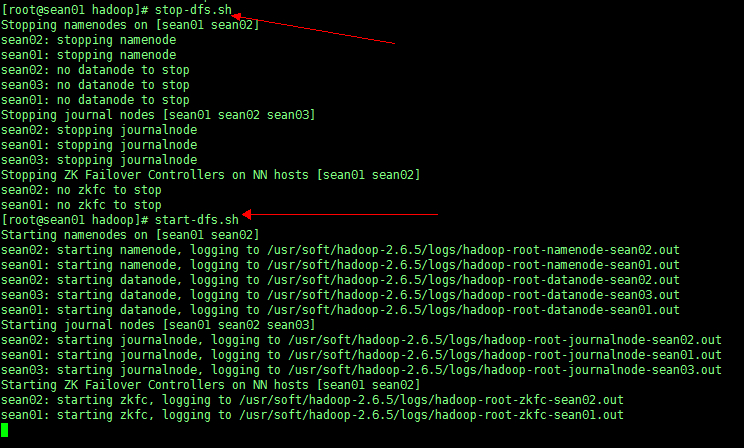
11、停止上面节点:stop-dfs.sh
12、全面启动:start-dfs.sh
浏览器打开两个 NamwNode Web端
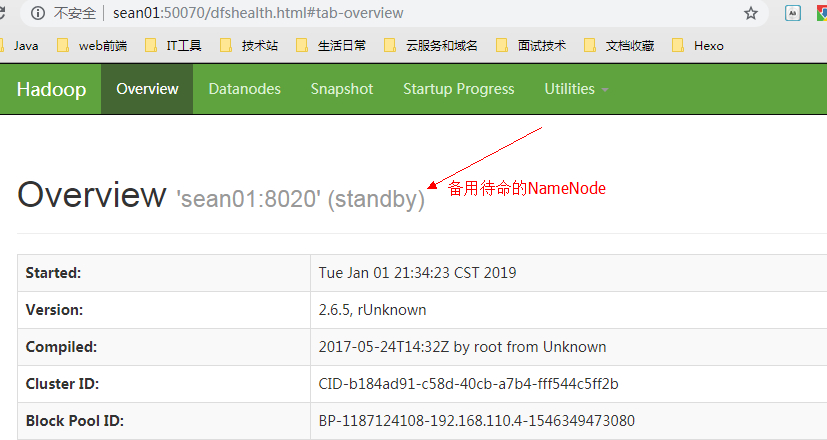
sean01
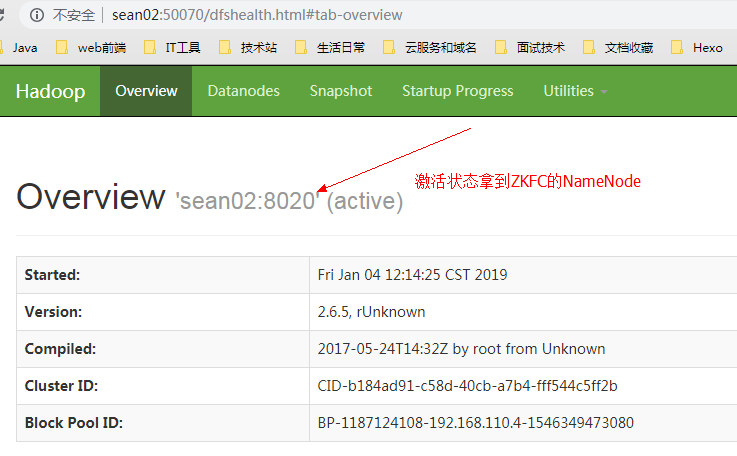
sean02
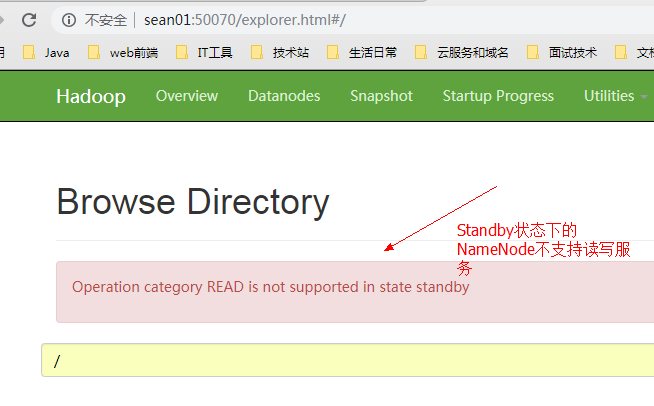
查看进程此时在两个 NN 下会多出 ZKFC 文件,就是竞争锁


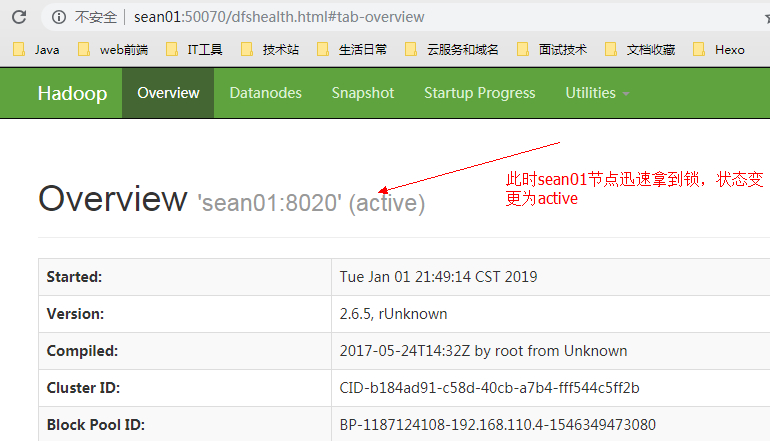
13、关闭此时处于 Active 状态的 NN 节点 sean02
hadoop-daemon.sh stop namenode |
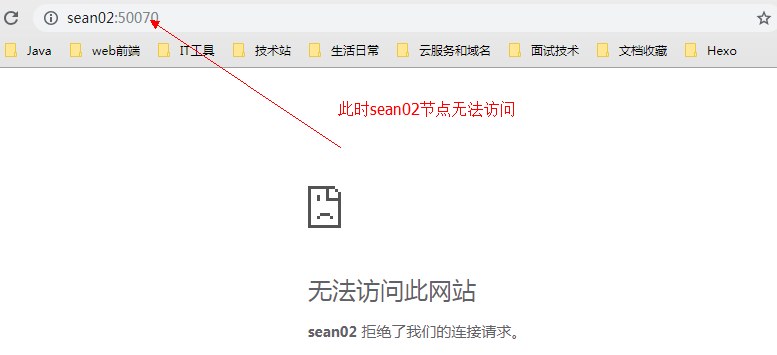
由于此时之前处于active的 NN 节点sean02已经挂掉,sean01迅速拿到竞争锁ZKFC,状态由standby变为active
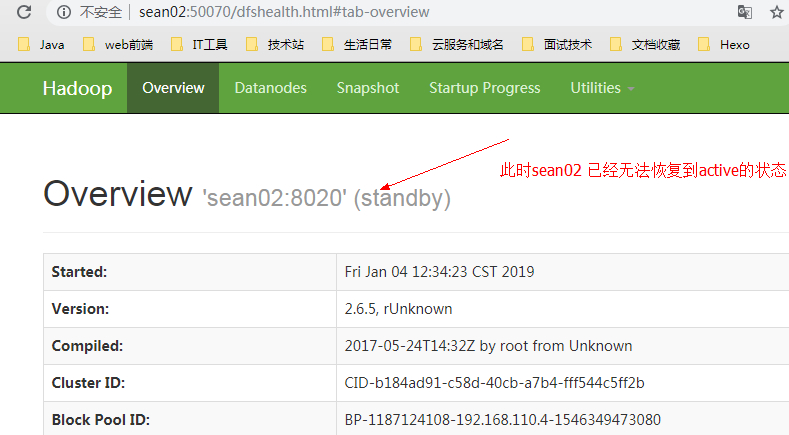
再重新启动 sean02 节点查看状态。
由于此时的竞争锁在节点sean01手中,所以sean02 节点无法恢复到active状态,只能为standby状态
14、查看 MapReduce 计算框架的状态。
yarn-daemon.sh start resourcemanager (启动资源管理器) |
可能出错的地方
1、确认每台机器防火墙均关掉
2、确认每台机器的时间是一致的
3、确认配置文件无误,并且确认每台机器上面的配置文件一样
4、如果还有问题想重新格式化,那么先把所有节点的进程关掉
5、删除之前格式化的数据目录hadoop.tmp.dir属性对应的目录,所有节点同步都删掉,别单删掉之前的一个,删掉三台JN节点中dfs.journalnode.edits.dir属性所对应的目录
6、接上面的第6步又可以重新格式化已经启动了
7、最终 Active Namenode 停掉的时候,StandBy 可以自动接管!
Hadoop集群脑裂问题
什么是脑裂
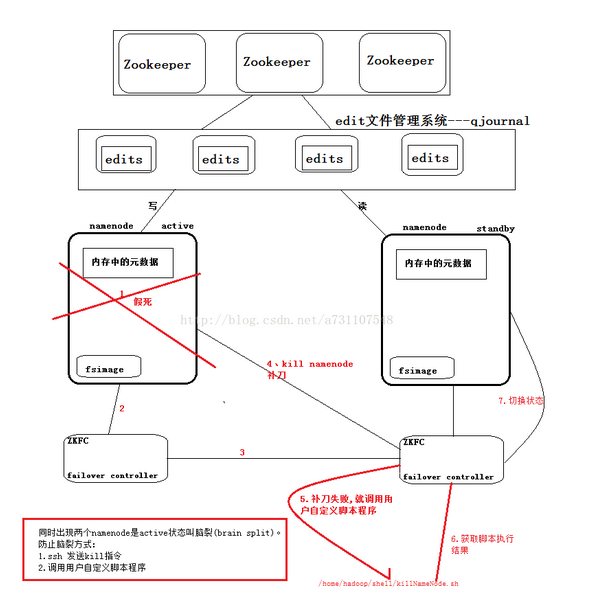
脑裂(brain-split):脑裂是指在主备切换时,由于切换不彻底或其他原因,导致客户端和 Slave 误以为出现两个active master,最终使得整个集群处于混乱状态。
如何解决集群脑裂问题
解决脑裂问题,通常采用隔离(Fencing)机制,包括三个方面:
- 共享存储fencing:确保只有一个Master往共享存储中写数据。
- 客户端fencing:确保只有一个Master可以响应客户端的请求。
- Slave fencing:确保只有一个Master可以向Slave下发命令。
Hadoop 公共库中对外提供了两种 fencing 实现,分别是 sshfence 和 shellfence(缺省实现),其中 sshfence 是指通过 ssh 登陆目标 Master 节点上,使用命令 fuser 将进程杀死(通过 tcp 端口号定位进程 pid,该方法比 jps 命令更准确),shellfence 是指执行一个用户事先定义的 shell 命令(脚本)完成隔离。
解决脑裂的两种方法:
1、通过 ssh 发送 kill 命令
2、调用用户自定义的脚本程序
 微信
微信 支付宝
支付宝



