
分布式计算框架MapReduce
MapReduce 是什么
1. 概念
MapReduce 是一种分布式的离线计算框架,是一种编程模型,用于大规模数据集(大于1TB)的并行运算。将自己的程序运行在分布式系统上。
**概念是:"Map(映射)“和"Reduce(归约)”。**指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
2. 应用场景
可应用于大规模的算法图形处理、文字处理。
MapReduce 的设计理念
1. 分布式计算
分布式计算将该应用分解成许多小的部分,分配给多台计算机节点进行处理。这样可以节约整体计算时间,大大提高计算效率。
2. 移动计算,而不是移动数据
移动计算是随着移动通信、互联网、数据库、分布式计算等技术的发展而兴起的新技术。移动计算它的作用是将有用、准确、及时的信息提供给任何时间、任何地点的任何客户(这里我们说的是将计算程序应用移动到具有数据的集群计算机节点之上进行计算操作,也就是:计算向数据靠拢)。
MapReduce 计算框架的组成

Mapper(分)
Map-Reduce的思想就好比太极又好比天下大势。合久必分,分久必合。
1. Mapper 负责“分”,即把得到的复杂的任务分解为若干个“简单的任务”执行。
“简单的任务”有几个含义:
1、数据或计算规模相对于原任务要大大缩小;
2、就近计算,即会被分配到存放了所需数据的节点进行计算;
3、这些小任务可以并行计算,彼此间几乎没有依赖关系
Split规则:
– max.split(100M)
– min.split(10M)
– block(128M)
max(min.split,min(max.split,block))
- split实际 = block大小
2. Map 的数目通常是由输入数据的大小决定的,一般就是所有输入文件的总块(block)数。
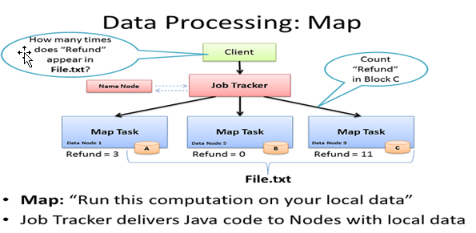
Reduce(合)
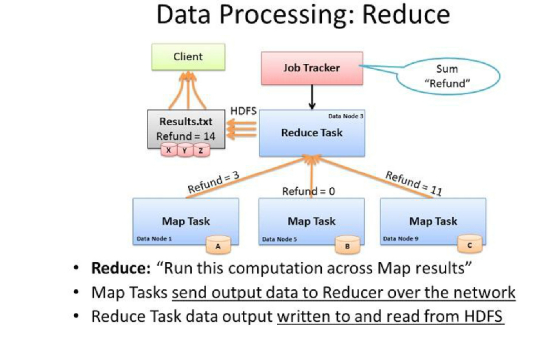
1. Reduce的任务是对map阶段的结果进行“汇总”并输出。
Reducer 的数目由 mapred-site.xml 配置文件里的项目mapred.reduce.tasks决定。缺省值为1,用户可以覆盖之。
Shuffle过程
在 Mapper 和 Reducer 中间的一个步骤,就是 Shuffle。
shuffle的作用:
(1) Shuffle 可以把 mapper 的输出按照某种 key 值重新切分和组合成 n 份,把 key 值符合某种范围的输出送到特定的 reducer 那里去处理。
(2) 可以简化 reducer 过程。
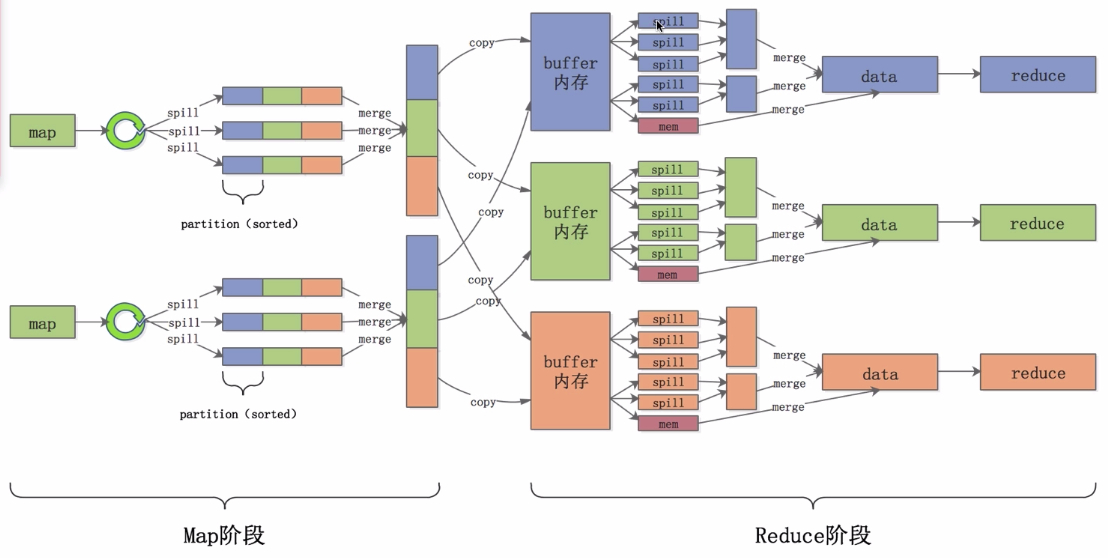
2. Shuffle的过程理解
Map 端:
1、Collec 阶段数据放在环形缓冲区,环形缓冲区分为数据区和索引区
2、Sort 阶段对在同一 partition 内的索引按照 key 值排序。
3、Spill(溢写)阶段根据拍好序的索引将数据按顺序写到文件中。
4、Merge 阶段将 Spill 生成的小文件分批合并排序(二次排序)成一个大文件。
Reduce 端:
1、Copy 阶段将Map段的数据分批拷贝到Reduce的缓冲区。
2、Spill 阶段将内存缓冲区的数据按照顺序写到文件中。
3、Merge 阶段将溢出文件合并成一个排好序的数据集。
Combine优化
整个过程中可以提前对聚合好的value值进行计算,这个过程就叫Combine。
map端
- 在数据排序后,溢写到磁盘前,相同key值的value是紧挨在一起的,可以进行聚合运算,运行一次combiner。
- 再合并溢出文件输出到磁盘前,如果存在至少3个溢出文件,则运行combiner,可以通过min.num.spills.for.combine设置阈值。
Reduce端
- 在合并溢出文件输出到磁盘前,运行combiner。
- Combiner不是任何情况下都适用的,需要根据业务需要进行设置。
MR 框架计算流程
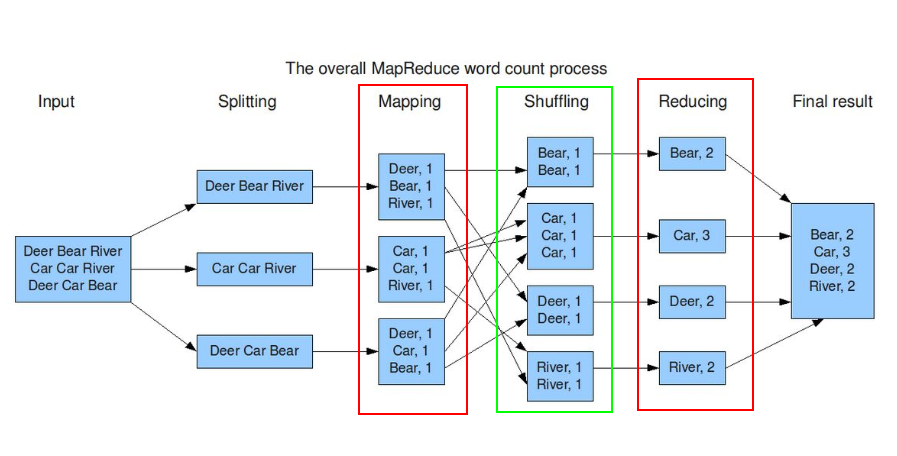
MR的具体执行步骤:
1、一个文件分成多个split数据片。
2、每个split由多一个map进行处理。
3、Map处理完一个数据就把处理结果放到一个环形缓冲区内存中。
4、环形缓冲区满后里面的数据会被溢写到一个个小文件中。
5、小文件会被合并成一个大文件,大文件会按照partition进行排序。
6、reduce节点将所有属于自己的数据从partition中拷贝到自己的缓冲区中,并进行合并。
7、最后合并后的数据交给reduce处理程序进行处理。处理后的结果存放到HDFS上。
**注意:**在 Map 阶段 如果存在大量重复的统计工作,就需要 Combiner了。 Combiner 继承的是 Reduce 类:作用是对 Map 的阶段聚合统计操作,减小后期 Reduce 的重复统计压力。
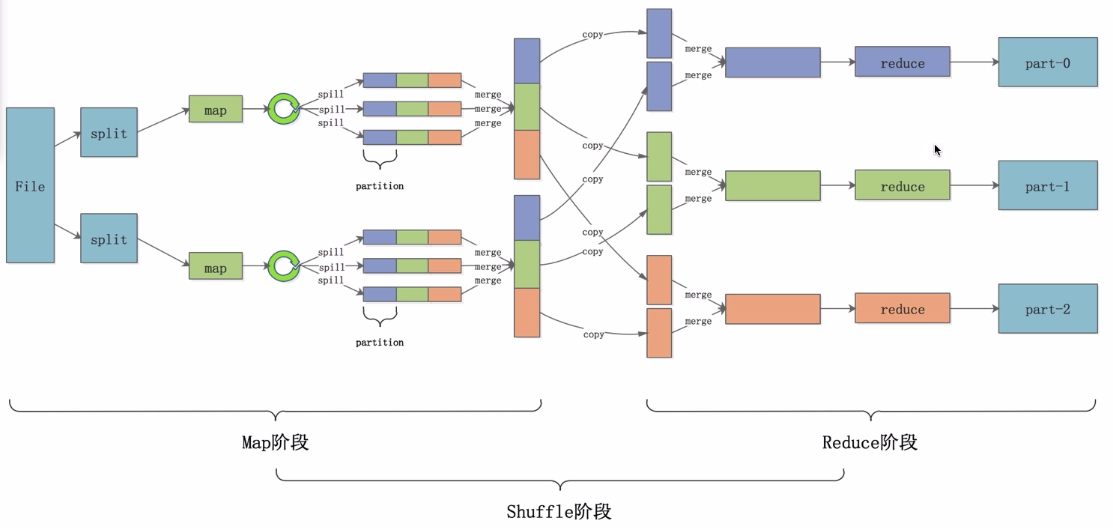
MR 架构
MapReduce 采用主从架构的架构思想,包括主(JobTracker)和从(TaskTracker)。
1. 主 JobTracker:RM(ResourceManager)
负责调度分配每一个子任务 task 运行于 TaskTracker上,如果发现有失败的task就重新分配其任务到其他节点。每一个 hadoop 集群中只一个 JobTracker,一般它运行在 Master 节点上。
2. 从 TaskTracker:NM(NodeManager)
TaskTracker 主动与 JobTracker 通信,接收作业,并负责直接执行每一个任务,为了减少网络带宽 TaskTracker 最好运行在 HDFS 的 DataNode 上。
MapReduce 环境配置及安装
1. 项目部署规划
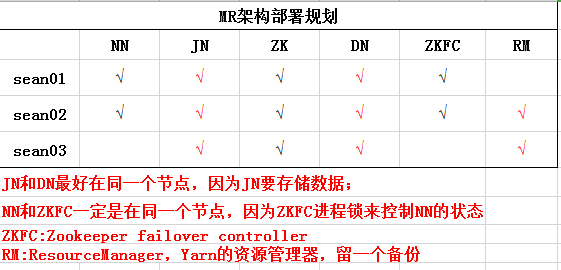
2. 具体步骤
1、关于Hadoop2.X集群的配置前面在前一期已做详细讲解,这里步骤相同。在保证 Hadoop 集群正常启动之后停掉 HA 集群。
2、配置 mapred-site.xml 和 yarn-site.xml 文件
mapred-site.xml
<configuration> |
yarn-site.xml
<configuration> |
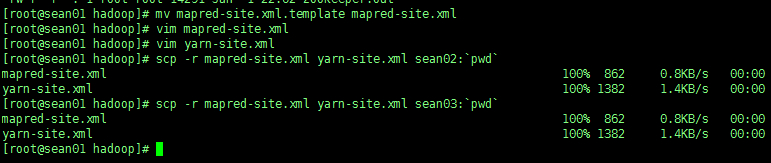
3、将节点 sean01 配置发送到另外两个节点
scp -r mapred-site.xml yarn-site.xml sean02:`pwd` |
4、分别启动3个节点的 Zookeeper
zkServer.sh start |

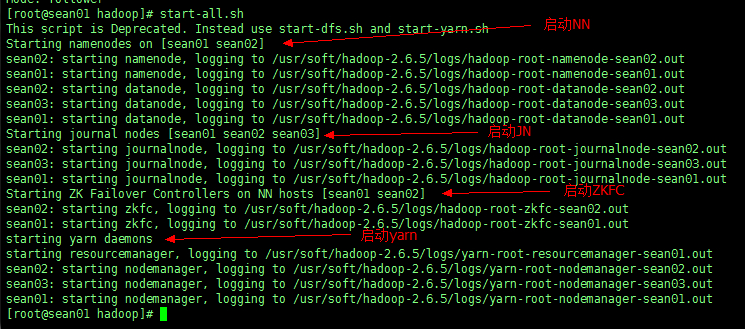
5、启动三个节点的 Hadoop
start-all.sh #这个命令相当于 start-dfs.sh + start-yarn.sh |
使用命令 jps 查看当前进程

这里会发现,虽然日志显示启动了ResourceManager,但进程中并没有,所以需要手动启动
6、手动启动节点 sean02 和 sean03 的 ResourceManager
yarn-daemon.sh start resourcemanager |
7、去浏览器web端查看
-
查看NameNode
sean01 节点
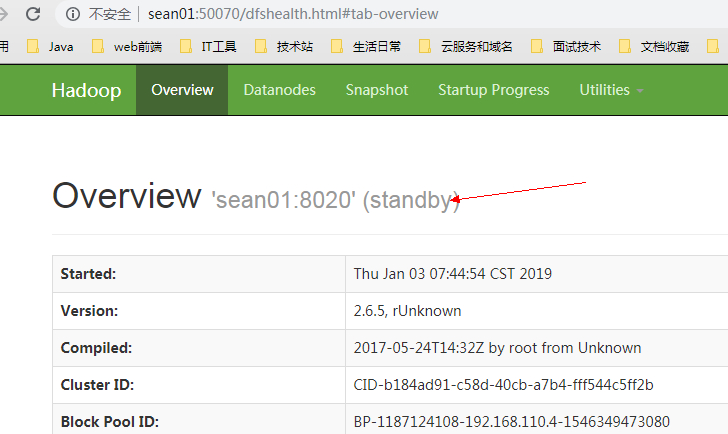
sean02 节点
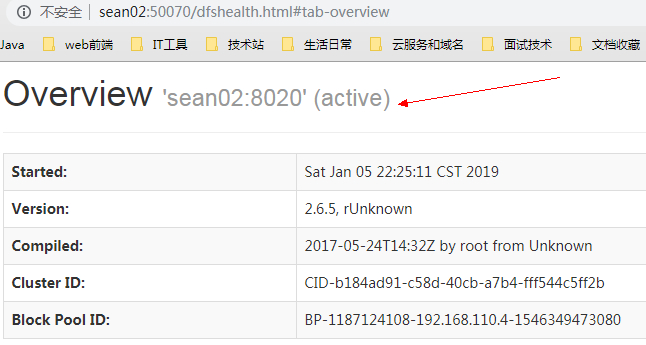
可以看出节点 sean02 为激活状态。
-
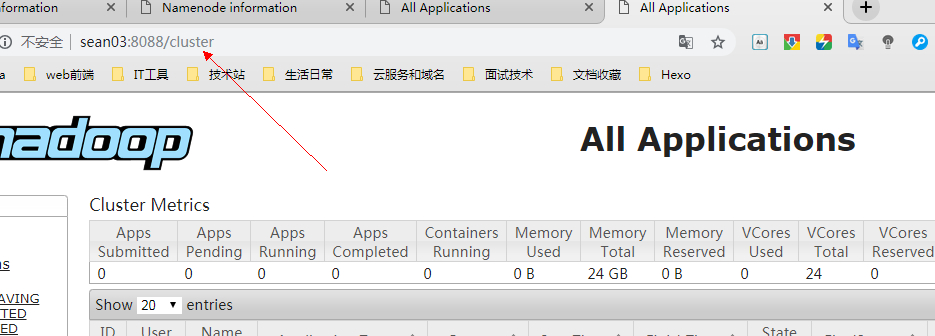
查看 ResourceManager
默认端口:8088
sean03节点
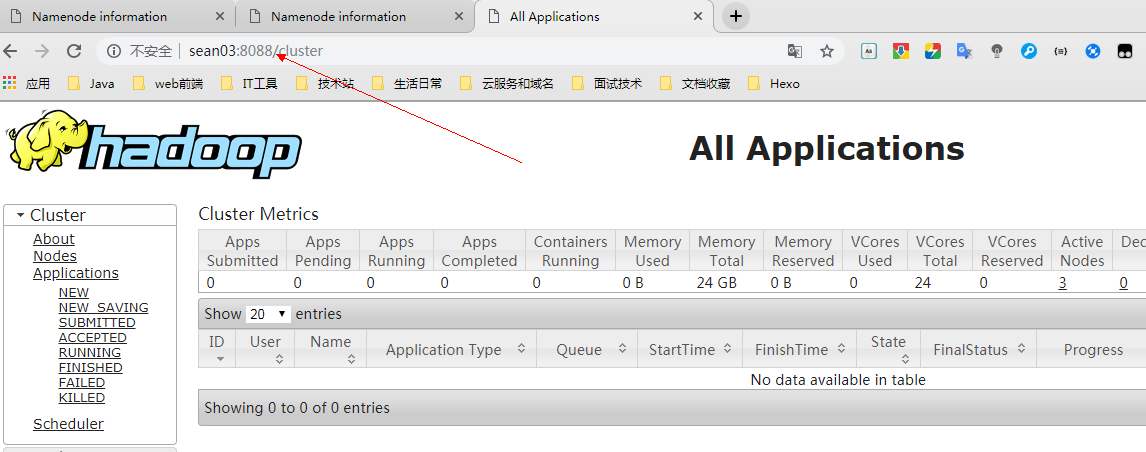
sean02节点
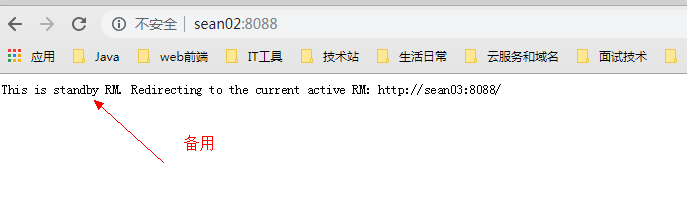
会发现由于节点 sean03 已经启动了 SM,所以后启动的节点 sean02 就成了备用。并且在片刻之后会跳转至具有 SM 的节点sean3。
8、关闭 MR 集群
注意关闭顺序:
- 先关Yarn再关hadoop再关Zookeeper,注意:在NN的节点上执行
stop-all.sh #代表关闭Hadoop和yarn的所有进程 |
- 再手动关闭Yarn的ResourceManager
yarn-daemon.sh stop resourcemanager |
- 再关掉三台几点的 Zookeeper
zkServer.sh stop |
最后查看进程确保全部关闭成功

 微信
微信 支付宝
支付宝



