
深入Zookeeper
什么是 Zookeeper
Zookeeper 简介
ZooKeeper 是一个开源的、分布式应用程序协调服务,是 Google 的 Chubby 一个开源的实现,是 Hadoop 和 Hbase 的重要组件。
它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
**ZooKeeper:**提供通用的分布式锁服务,用以协调分布式应用。
**Keepalived:**监控节点不好管理,采用优先级监控。但是没有协同工作;功能单一;可扩展性差。
Zookeeper 的角色
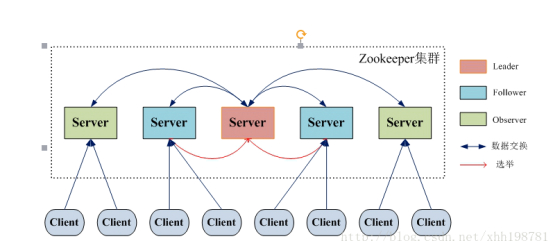
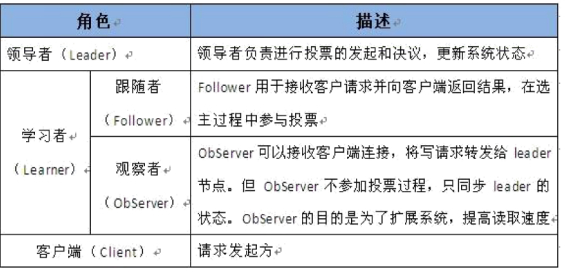
领导者(leader),负责进行投票的发起和决议,更新系统状态。
学习者(learner),包括跟随者(follower)和观察者(observer), follower 用于接受客户端请求并想客户端返回结果,在选主过程中参与投票。
**Observer **可以接受客户端连接,将写请求转发给leader,但observer不参加投票过程,只同步 leader 的状态,observer 的目的是为了扩展系统,提高读取速度。
Zookeeper 需保证高可用和强一致性;为了支持更多的客户端,需要增加更多Server;Server增多,投票阶段延迟增大,影响性能;
(1) 权衡伸缩性和高吞吐率,引入 Observer。
(2) Observers 接受客户端的连接,并将写请求转发给 leader 节点;加入更多Observer 节点,提高伸缩性,同时不影响吞吐率。
Zookeeper 的特点

Zookeeper 的安装配置
深入 Zookeeper 原理,Paxos 算法
Zookeeper 的节点及工作原理
Zookeeper节点
1. 节点分类
(1) 短暂的(ephemeral)
- 短暂 znode 的客户端会话结束时,zookeeper 会将该短暂 znode 删除,短暂 znode 不可以有子节点。
(2) 持久的(persistent)
- 持久 znode 不依赖于客户端会话,只有当客户端明确要删除该持久 znode 时才会被删除。
2. 目录节点
Znode又有四种形式的目录节点:
PERSISTENT 持久的
EPHEMERAL 短暂的
PERSISTENT_SEQUENTIAL 持久且有序的
EPHEMERAL_SEQUENTIAL 短暂且有序的
注意:Znode 的类型在创建时确定并且之后不能再修改
Zookeeper工作原理
(1) 每个Server在内存中存储了一份数据;
(2) Zookeeper启动时,将从实例中选举一个leader(Paxos协议)
(3) Leader负责处理数据更新等操作
(4) 一个更新操作成功,当且仅当大多数Server在内存中成功修改数据。
Zookeeper的核心是原子广播,这个机制保证了各个server之间的同步。实现这个机制的协议叫做Zab协议。
Zab协议有两种模式,它们分别是恢复模式和广播模式。
当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数server的完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和server具有相同的系统状态。一旦leader已经和多数的follower进行了状态同步后,他就可以开始广播消息了,即进入广播状态。这时候当一个server加入zookeeper服务中,它会在恢复模式下启动,发现leader,并和leader进行状态同步。待到同步结束,它也参与消息广播。Zookeeper服务一直维持在Broadcast状态,直到leader崩溃了或者leader失去了大部分的followers支持.
广播模式需要保证proposal被按顺序处理,因此zk采用了**递增的事务id号(zxid)**来保证。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch。低32位是个递增计数。
当leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的server都恢复到一个正确的状态。
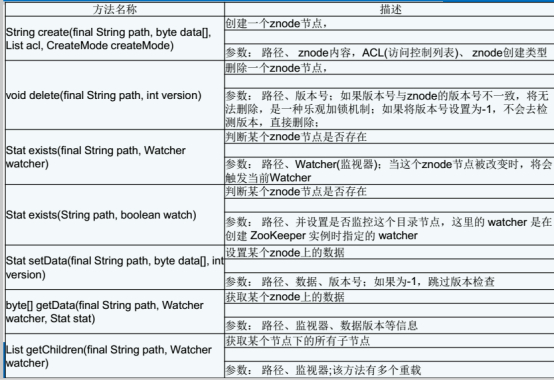
Zookeeper 的方法(API)
 微信
微信 支付宝
支付宝



