
Hadoop之数据仓库Hive
Hive 及数据仓库简介
基本概念
Hive 是基于 Hadoop 的一个【数据仓库工具】,可以将结构化的数据文件映射为一张 hive 数据库表,并提供简单的 sql 查询功能,可以将 sql 语句转换为 MapReduce 任务进行运行。
【数据仓库】英文名称为 Data Warehouse,可简写为DW或 DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
**Hive 的表其实就是HDFS的目录/文件夹,hive表中的数据 就是hdfs目录中的文件,并按表名把文件夹分开。**如果是分区表,则分区值是子文件夹,可以直接在M/R job里使用这些数据。
Hive 的优缺点
**优点:**使用SQL来快速实现简单的 MapReduce 统计,不必开发专门的 MapReduce 应用,学习成本低,十分适合数据仓库的统计分析。
**缺点:**只适合离线的数据处理,不支持实时查询。
Hive与HBase的关系与区别
关系:
-
Hive与HBase其实没有必然的关系,但是由于HBase的查询语句很不好用,所以可以通过整合Hive,对存储在Hadoop群上的数据提供类SQL的接口进行操作,也就是利用Hive来操作HBase数据库。
-
他们的共同点是数据都存储在HDFS,也就是说他们都是建立于Hadoop之上。
区别:
- 如果你有数据仓库的需求并且你擅长写SQL并且不想写MapReduce jobs就可以用Hive代替。用 HiveQL进行select,join,等等操作。但是Hive只适合做离线的批处理,实时性不高。
- HBase是一个分布式的NoSql数据库,像其他数据库一样提供随即读写功能。如果你需要实时访问一些数据,就把它存入HBase。你可以用Hadoop作为静态数据仓库,HBase作为数据存储,放那些进行一些操作会改变的数据。
数据处理的分类
1. 联机事务处理OLTP(on-line transaction processing)
OLTP 是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。
OLTP 系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作。
2. 联机分析处理OLAP(On-Line Analytical Processing)
OLAP 是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLAP 系统则强调数据分析,强调 SQL 执行市场,强调磁盘 I/O,强调分区等。
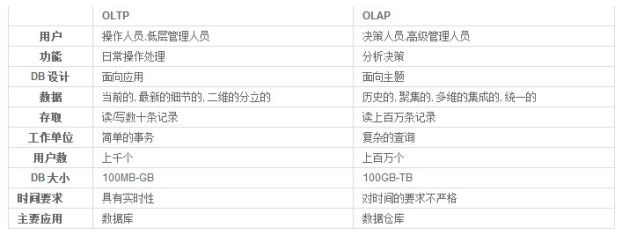
简而言之,数据仓库是用来做查询分析的数据库,基本不用来做插入,修改,删除操作。
-
Hive:数据仓库。
-
Hive:解释器,编译器,优化器等。
-
Hive 运行时,元数据存储在关系型数据库里面。
-
编译器将一个Hive SQL转换操作符,操作符是Hive的最小的处理单元
每个操作符代表HDFS的一个操作或者一道MapReduce作业。
Hive 架构原理
1. 用户接口
用户接口主要有三个:Client CLI、JDBC/ODBC 和 WEBUI。

-
**Client CLI :**Hive shell 命令行,最常用。Client 是 Hive 的客户端,用户连接至 Hive Server。在启动 Client 模式的时候,需要指出 Hive Server 所在节点,并且在该节点启动 Hive Server。
-
**JDBC/ODBC:**Hive的 Java 实现,与传统数据库 JDBC 类似。
-
**WEBUI:**通过浏览器访问 Hive。
2. 元数据存储
Hive 将元数据存储在关系型数据库中,如 mysql、oracle、derby 。 Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
3. 驱动器(Driver)
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce调用执行。
4. 数据存储
Hive 的数据存储在 HDFS 中。大部分的查询、计算由 MapReduce 完成(包含 * 的查询,比如 select * from tb 不会生成 MapRedcue 任务)
Hive 搭建及三种模式
Hive 的安装配置
1、安装Hive
安装环境以及前提说明:首先,Hive 是依赖于 hadoop 系统的,因此在运行 Hive 之前需要保证已经搭建好 hadoop 集群环境。
- 并安装好一个关系型数据:如 mysql
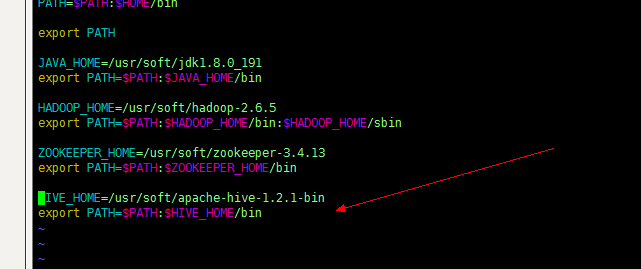
2、配置环境变量
– HADOOP_HOME=/xxx
– HIVE_HOME=/xxx
这里选择配置局部的环境变量,编辑 ~/.bash_profile,具体操作参考我的另一篇文章 Linux常用操作个人整理
3、替换和添加相关jar包
(1) 修改 Hadoop安装包下 /share/hadoop/yarn/lib 目录下的 jline-*.jar
将其替换成 HIVE_HOME/lib 下的 jline-2.12.jar
(2) 将 hive 连接 mysql 的jar包:mysql-connector-java-5.1.32-bin.jar
拷贝到hive解压目录的lib目录下
4、修改配置文件(选择3种模式里的一种)见三种安装模式
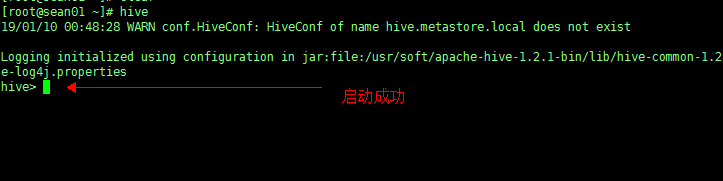
5、启动 hive
配置完环境变量,可以在任意客户端的节点上直接输入命令:hive
即可启动。
Hive 配置的三种模式
新建配置文件 hive-site.xml 在 Hive 安装包下的 conf 目录中。
A、内嵌模式(元数据保存在内嵌的derby中,允许一个会话链接,尝试多个会话链接时会报错)【不推荐】
B、本地模式(本地安装mysql 替代derby存储元数据)【推荐】
C、远程模式(远程安装mysql 替代derby存储元数据)【推荐】
1. 内嵌Derby单用户模式
这种安装模式的元数据是内嵌在Derby数据库中的,只能允许一个会话连接,数据会存放到HDFS上。
这种方式是最简单的存储方式,只需要hive-site.xml 做如下配置便可(注:使用 derby 存储方式时,运行 hive 会在当前目录生成一个 derby 文件和一个 metastore_db)。
<!-- 内嵌模式 --> |
2. 本地用户模式
这种安装方式和嵌入式的区别在于:不再使用内嵌的Derby作为元数据的存储介质,而是使用其他数据库比如 MySQL 来存储元数据且是一个多用户的模式,运行多个用户 client 连接到一个数据库中。这种方式一般作为公司内部同时使用 Hive。这里有一个前提,每一个用户必须要有对MySQL的访问权利,即每一个客户端使用者需要知道MySQL的用户名和密码才行。
这种存储方式需要在本地运行一个 mysql 服务器,并作如下配置(下面两种使用 mysql 的方式,需要将 mysql 的 jar 包拷贝到 Hive 安装包下的 lib 目录下。
hive-site.xml 配置如下:
<!-- 1.本地模式 --> |
注意:hive和MySQL不用做HA,单节点就可以。通过设置其他节点可以访问得到数据库。
3. 远程模式
远程模式又分为两种:远程一体和远程分开
(1) 远程一体模式
这种存储方式需要在远端服务器运行一个 mysql 服务器,并且需要在 Hive 服务器启动 meta服务。
<!-- 远程一体模式 --> |
注:这里把 hive 的服务端和客户端都放在同一台服务器上了。
(2) 远程分开模式
所谓远程分开模式就是在远程的前提下,把 Hive 的服务端和客户端分开放到两个不同的服务器节点上。
服务端
|
客户端
|
**注意启动:**必须先启动服务端,再启动客户端,否则会报错!
服务端:
hive --service metastore |
客户端:直接敲 hive 即可启动
HQL 操作
DDL 语句
Hive 的数据定义语言 ([LanguageManual DDL](javascript:changelink(‘https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL’,'EN2ZH_CN’);))
具体参见:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
重点是 hive 的建表语句和分区。
创建/删除/修改/使用数据库
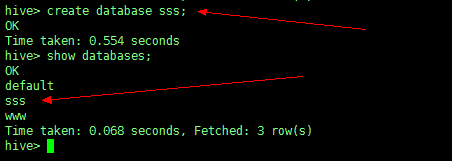
1、创建数据库(常用)
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name [COMMENT database_comment]; |
如图:创建了一个名叫 sss 的数据库
查看:show databases;
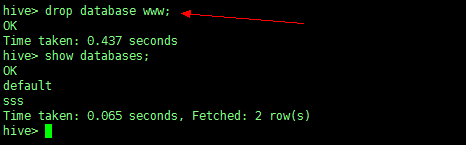
2、删除数据库(不常用)
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name; |
删除一个名叫 www 的数据库
3、修改表数据库(不常用)
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, ...); |
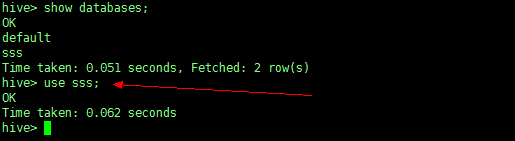
4、使用数据库
use database_name; |
创建、删除表
1、创建表(常用)
(1) 数据类型(data_type)
- primitive_type 原始数据类型
- array_type 数组
- map_type map
- struct_type
- union_type – (Note: Available in Hive 0.7.0 and later)
原始数据类型 primitive_type
-
TINYINT
-
SMALLINT
-
INT
-
BIGINT
-
BOOLEAN
-
FLOAT
-
DOUBLE
-
DOUBLE PRECISION
-
STRING 基本可以搞定一切
-
BINARY
-
TIMESTAMP
-
DECIMAL
-
DECIMAL(precision, scale)
-
DATE
-
VARCHAR
-
CHAR
数组(array_type)
- ARRAY < data_type >
map(map_type)
- MAP < primitive_type, data_type >
struct_type
- STRUCT < col_name : data_type [COMMENT col_comment], …>
union_type
- UNIONTYPE < data_type, data_type, … >
(2) 完整的建表语句
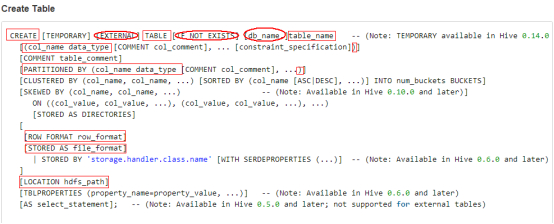

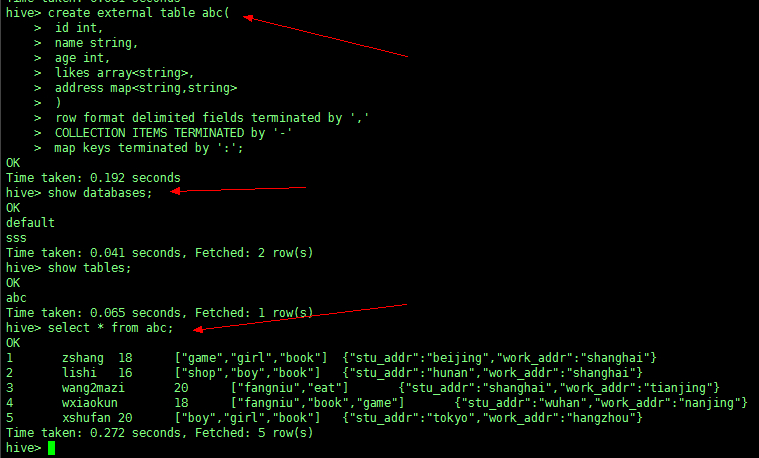
(3) 建表实例:
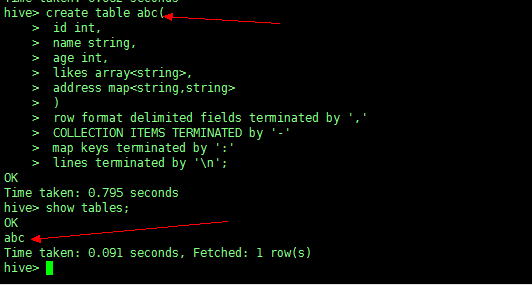
create table abc( |
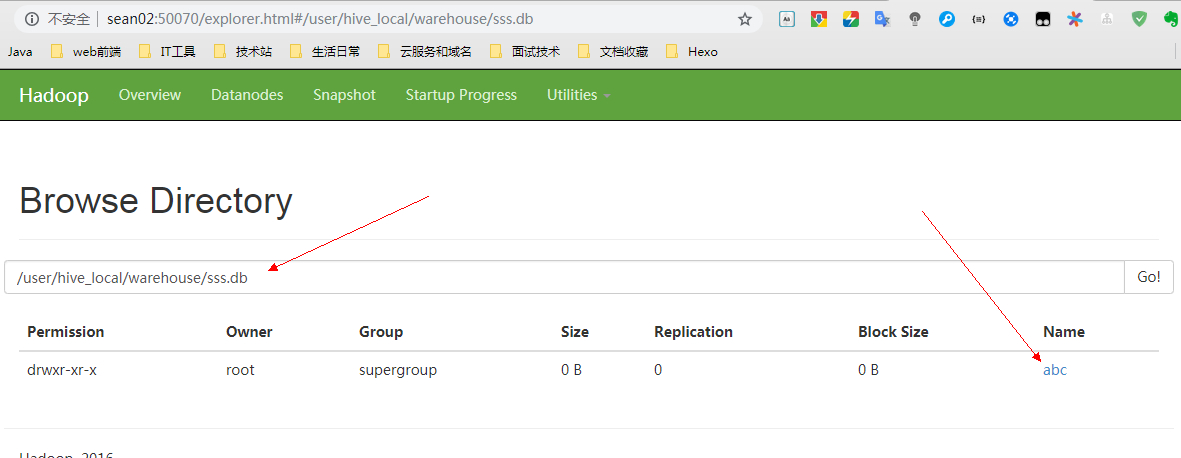
同时在 NameNode 的 HDFS 上也可以看到创建的表路径
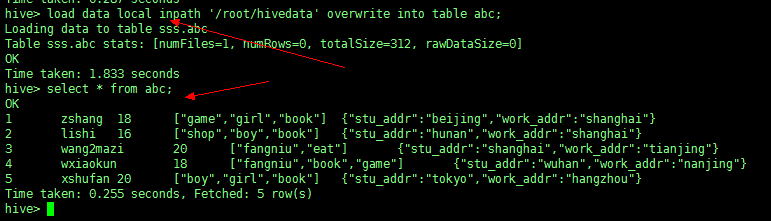
(4) 导入数据(属于DML但是为了演示需要在此应用):
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] |
数据如下:
1,zshang,18,game-girl-book,stu_addr:beijing-work_addr:shanghai |
首先在本地新建一个文件来装这些数据 :vim hivedata
然后加载到 abc 这张表中
load data local inpath '/root/hivedata' overwrite into table abc; |
注意:如果不加 local 加载的就不是本地,是加载 HDFS 上的文件
在之前的版本,需要在路径中写全 hdfs 的路径(加上集群的名称),现在新的版本已经优化了,不加 local 就是在 hdfs 上找,加了就会到本地服务器上找。
load data inpath 'hdfs://Xss/hivedata' overwrite into table abc; |
2、删除表
(1) 使用 Hive 删除表
DROP TABLE [IF EXISTS] table_name [PURGE]; |
比如删除刚刚创建的表 abc

(2) 使用 hdfs 删除表
因为 Hive 的元数据信息存储在 mysql 上,而数据存储在 HDFS 上,所以如果用 hdfs 的命令来删除表,会删除表里的数据,并不能删除元数据信息。
试验一下:我们用 hdfs 删除 abc 里的数据,然后重新把数据加载回来
hdfs dfs -rm -r /user/hive_local/warehouse/sss.db/abc/hivedata |

删除之后 hive 中就无法查找到结果

使用 hdfs 把数据 put 回来
hdfs dfs -put hivedata /user/hive_local/warehouse/sss.db/abc |
再次查看时,数据重新回来!

注意区别:
1、HDFS 删除的是表里的数据,不会删除表的元数据信息;
2、Hive删除普通表会把数据连带元数据信息一并删除;
3、Hive删除外部表只会删除元数据信息,不会删除数据。
因为 HDFS 删除和 Hive 删除普通表直接会删除数据,数据很重要,所以慎用!!!
使用 hive 删除普通表就会连带表的元数据信息彻底的删除。所以为了防止使用 hive 时避免误删,我们引入外部表来控制 hive 删除表的操作。
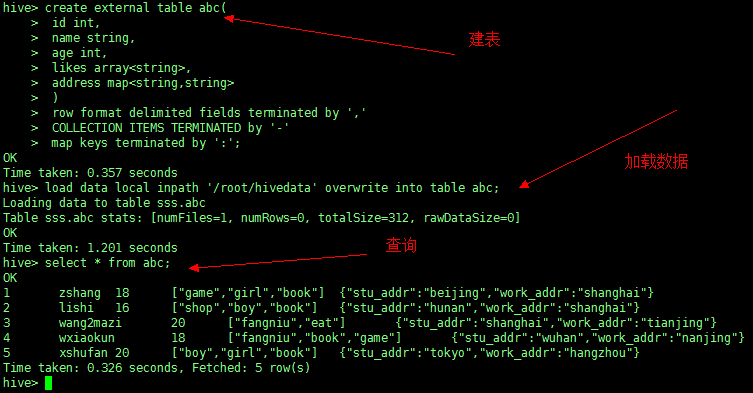
3、外部表
外部关键字 EXTERNAL 允许您创建一个表,并提供一个位置,以便 hive 不使用这个表的默认位置。这方便如果你已经生成的数据。当删除一个外部表,表中的数据不是从文件系统中删除。外部表指向任何 HDFS 的存储位置,而不是存储在配置属性指定的文件夹 hive.metastore.warehouse.dir 中。
开始创建外部表,需要在create 前加上关键字 external
create external table person( |
加载数据
load data local inpath '/root/hivedata' overwrite into table abc; |
然后使用 hive 删除表 abc
查询 mysql 数据库,发现元数据信息已经没有了

再看 HDFS 中,数据却还在
因为数据还在,于是只需要重新创建一下这个表就可以了
修改、更新表,删除表数据
这些一般工作中很少用
- 重命名表
ALTER TABLE table_name RENAME TO new_table_name; |
- 更新数据
UPDATE table_name SET column = value [, column = value ...] [WHERE expression] |
- 删除表数据
DELETE FROM table_name [WHERE expression] # 需要配置权限 |
DML 语句
Hive数据操作语言([LanguageManual DML](javascript:changelink(‘https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DML’,'EN2ZH_CN’);))
具体参见:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DML
重点是数据加载和查询插入语法
四种插入/导入数据
Hive 不能很好的支持用 insert 语句一条一条的进行插入操作,不支持 update 。数据是以 load 的方式加载到建立好的表中。数据一旦导入就不可以修改。
注意区分:在load数据时使用的是[overwrite] into,但是插入数据时是insert overwrite/into
第一种
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] |
第二种
INSERT OVERWRITE TABLE person |
先创建一个 person 表
create external table person( |
再把 abc 表里的数据插入到 person 表中
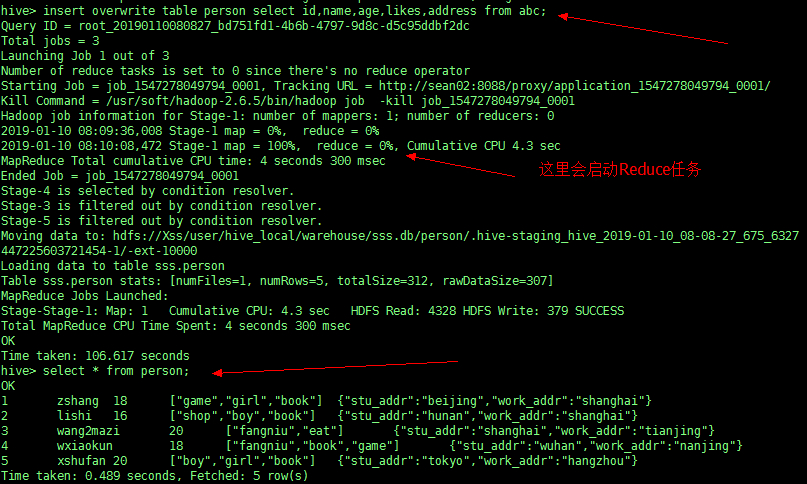
第三种
FROM person t1 |
先创建 person2 这个表
create table person2( |
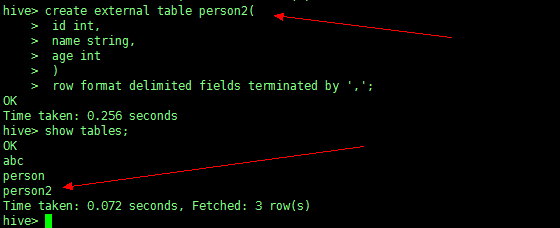
再插入 person 表中所需的三个字段的数据,得到数据。
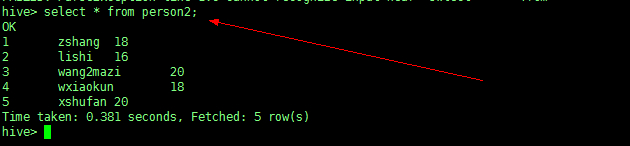
【from放前面好处就是后面可以插入多条语句 】
第四种

拓展:本地load数据和从HDFS上load数据的过程有什么区别?
本地: load 会自动复制到 HDFS 上的 hive 的 ** 目录下
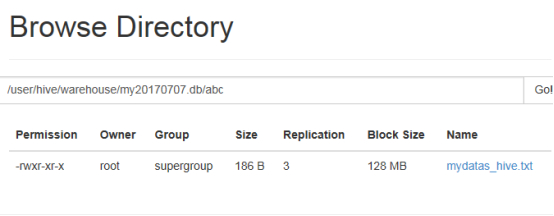
HDFS:load 会移动数据到 HDFS 上的 hive 的 ** 目录下,原来的就没有了。
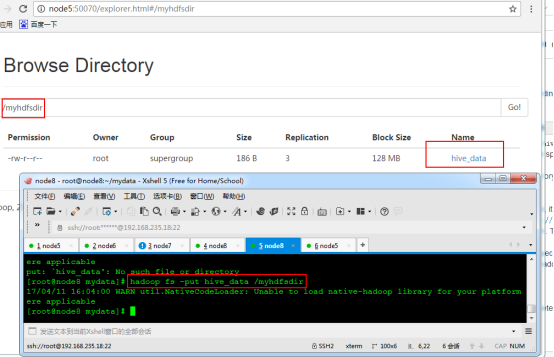
查询数据并保存
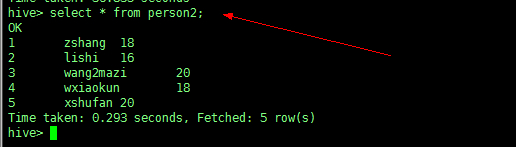
举例:我们用 person2 这张表作为查询对象
先查看一下 person2 表的数据信息
A、保存数据到本地
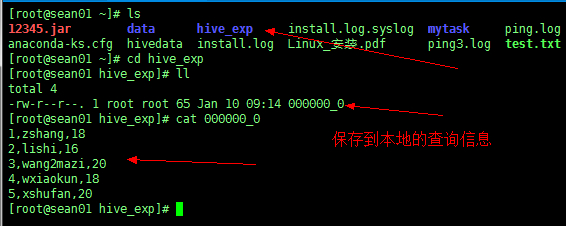
将 person2 表的查询信息保存到本地目录的 /root/hive_exp 下
insert overwrite local directory '/root/hive_exp' |
然后查看本地
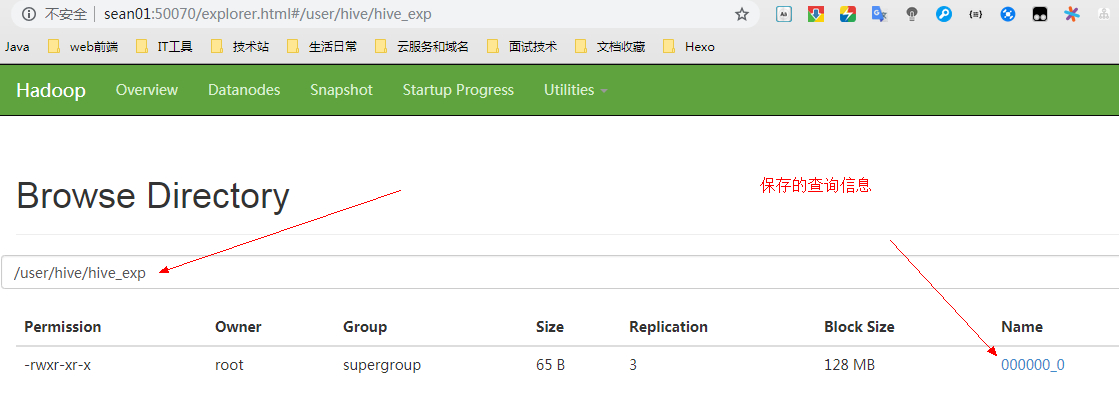
B、保存到 HDFS 上
将 person2 表的查询信息保存到 HDFS 目录的 /user/hive/hive_exp下
insert overwrite directory '/user/hive/hive_exp' |
然后查看 HDFS
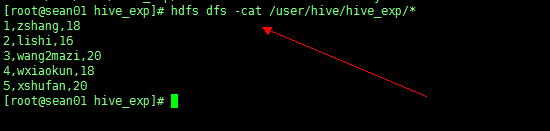
C、在外部 shell 中将数据重定向到文件中
有时我们在外部想利用 sql 查询表数据信息,但是又不想进到 hive 里面去,就可以用到外部 shell 的操作
比如:把 abc 这张表的数据标准输出重定向到本地 root 目录下的 abc.txt 文件中
hive -e "select * from sss.abc;" > /root/abc.txt #注意表明前一定要带上数据库的名称,否则会找不到而报错! |

备份数据或还原数据
1、备份数据
备份使用关键字export
举例:将person2表中的数据备份到 HDFS 中的目录 /user/hadoop/hive/datas 下
EXPORT TABLE person2 TO '/user/hadoop/hive/datas'; |
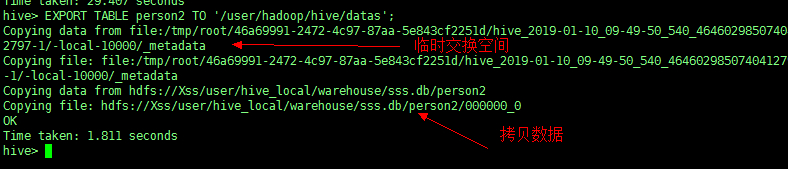
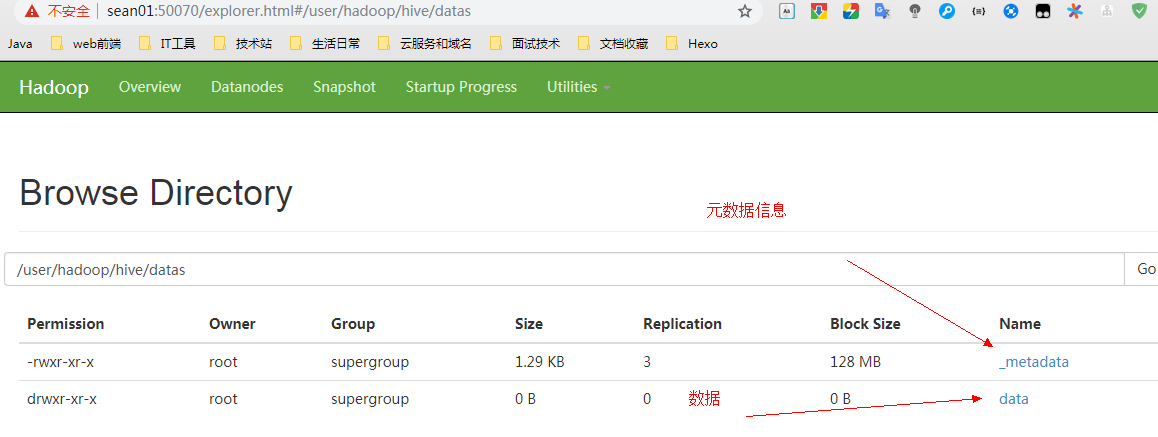
2、删除再还原数据
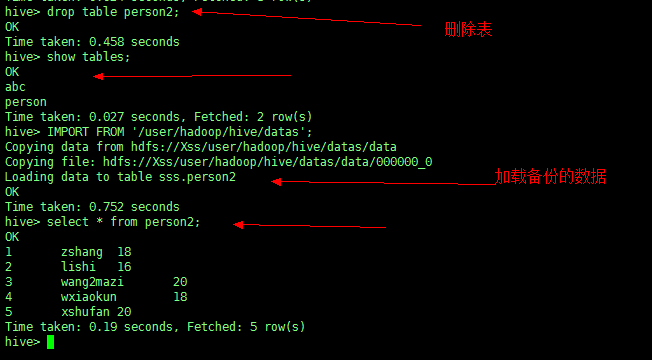
先删除表
drop table person2; |
再还原数据
IMPORT FROM '/user/hadoop/hive/datas'; |
Hive SerDe
Hive SerDe(Serializer and Deserializer),SerDe 用于做序列化和反序列化。
构建在数据存储和执行引擎之间,对两者实现解耦。
Hive 通过 ROW FORMAT DELIMITED 以及 SERDE 进行内容的读写。
1、格式:
row_format |
2、举例:处理一些请求数据,对数据做固定格式的清洗
表数据文件:localhost_access_log.2016-02-29.txt
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-upper.png HTTP/1.1" 304 - |
创建表
Hive 正则匹配(去掉中括号和 “ ” 号)
CREATE TABLE logtbl ( |
把数据文件上传数据到服务器,然后加载到表中
load data local inpath '/root/localhost_access_log.2016-02-29.txt' into table logtbl; |
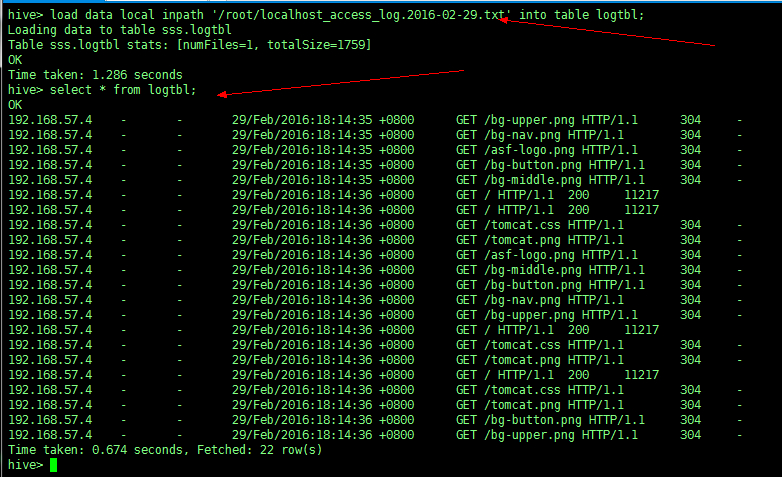
Beeline 和 Hiveser2
Hiveserver2 是 Hive server的第二个版本。
1、Hiveserver2 启动。
在服务端直接使用命令 hiveserver2 即可

Beeline 是 在 Hive 里的,他在 Hive 安装包下的 bin 目录下
2、启动 Beeline。
所以只要有 Hive 就能启动 Beeline,无论是分开模式还是一体模式。
3、Beeline 连接 hiveserver2
!connect jdbc:hive2://sean01:10000 root 123456 #连接mysql数据库 |
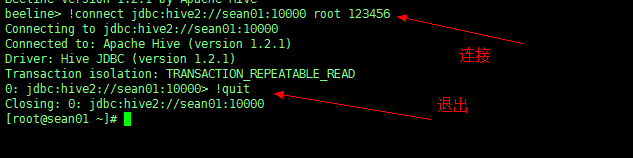
4、使用 Beeline 查询
查看效果:会发现 Beeline 在格式上进行了美化,也算是优化

注意:在实际工作中,Beeline并不怎么用,因为非常格式上要进行切分,非常消耗资源。
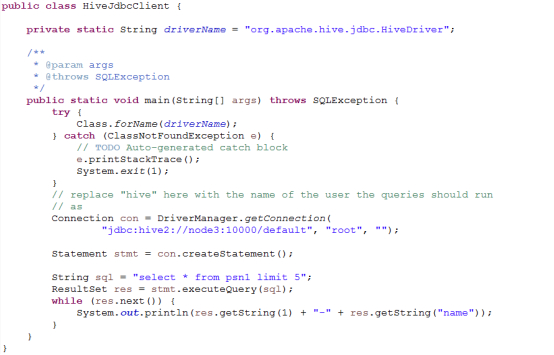
Hive 的 JDBC
一般是平台使用展示或接口,服务端启动hiveserver2后,在java代码中通过调用hive的jdbc访问默认端口10000进行连接、访问。(这种格式使用的比较少)
Hive 分区与自定义函数
Hive 的分区(partiton)
假如现在我们公司一天产生3亿的数据量,那么为了方便管理和查询,此时可以建立分区(可按日期 部门等具体业务分区)。分门别类的管理。
注意:必须在表定义时创建 partition !
分区分为:单分区和多分区
分区分为:静态分区和动态分区
创建分区
A、单分区建表语句
create table day_table(id int, content string) |
【单分区表,按天分区,在表结构中存在id,content,dt三列;以dt为文件夹区分】
新建数据文件 hivedata2 在本地 root 下
加载数据到分区表中
load data local inpath '/root/hivedata2' into table day_table partition(dt='2008-08-08'); |
查看表信息
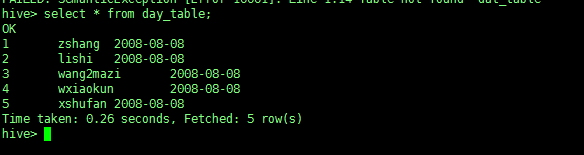
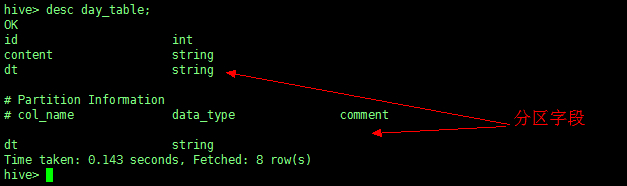
查看表结构(使用关键字 desc)
查看 HDFS

注意:在 HDFS 中不能用‘/’和‘-’连接字段,否则会乱码。

B、双分区建表语句
create table day_hour_table (id int, content string) |
【双分区表,按天和小时分区,在表结构中新增加了dt和hour两列;先以dt为文件夹,再以hour子文件夹区分】
加载数据到双分区表中
load data local inpath '/root/hivedata2' into table day_hour_table partition(dt='2008-08-08',hour='01-02'); |
查看表信息
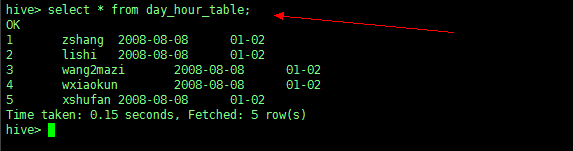
查看 HDFS

注意:在创建 删除多分区等操作时一定要注意分区的先后顺序,他们是父子节点的关系。分区字段不要和表字段相同
添加分区表的分区字段
表分区已创建,在此基础上添加具体分区。
比如在建表的时候就已经定义了分区:partitioned by(dt string),我们可以根据这个类型新建多个分区字段,比如按天去分区,每天就是一个文件夹。
语法格式
ALTER TABLE table_name |
例:
alter table day_table add partition(dt='2008-08-08'); |
添加的前提是表在创建时已经定义了相应的分区。比如:添加一个单分区字段,前提是在创建这张表时已经定义了这个单分区,多分区同理。
删除分区
语法格式
ALTER TABLE table_name DROP partition_spec, partition_spec,... |
用户可以用 ALTER TABLE DROP PARTITION 来删除分区。分区的元数据和数据将被一并删除。
例:
alter table day_hour_table drop partition(dt='2008-08-08'); |
数据加载进分区表中
语法格式
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1,partcol2=val2 ...)] |
例如
load data local inpath '/root/hivedata2' into table day_table partition(dt='2008-08-08'); |
当数据被加载至表中时,不会对数据进行任何转换,Load操作只是将数据复制至Hive表对应的位置。
数据加载时在表下自动创建一个目录基于分区的查询的语句:
select * from day_table where day_table.dt >= '2008-08-08' |
查看分区语句
例如:
hive> show partitions day_hour_table; |
重命名分区
语法格式
ALTER TABLE table_name PARTITION partition_spec RENAME TO PARTITION partition_spec; |
例如
alter table day_table partition (tian='2018-05-01') rename to partition (tain='2018-06-01'); |
动态分区
1、创建数据
在本地文件 /root/hivedata3 中写入以下4行数据
aaa,US,CA |
2、建立非分区表并加载数据
创建表 t1
CREATE TABLE t1 (name STRING, cty STRING, st STRING) |
加载数据 hivedata3
LOAD DATA LOCAL INPATH '/root/hivedata3' INTO TABLE t1; |
查询 t1
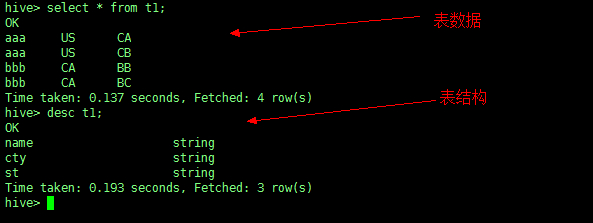
3、创建外部分区表(普通分区表也可以)
CREATE EXTERNAL TABLE t2 (name STRING) PARTITIONED BY (country STRING, state STRING); |
这时就需要使用动态分区来实现。
使用动态分区需要注意设定以下参数:
- hive.exec.dynamic.partition |
比如设定 当前动态分区的模式为非严格模式 nonstrict

4、插入数据
将 t1 表的数据动态插入到 t2 表中
INSERT INTO TABLE t2 PARTITION (country, state) SELECT name, cty, st FROM t1; |
查询 t2
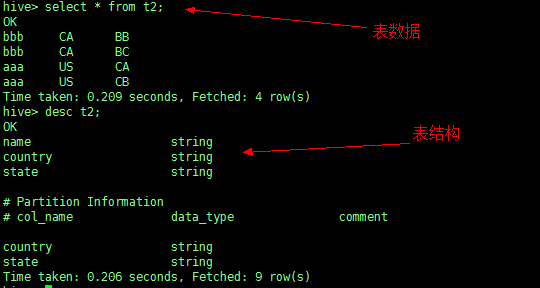
自定义函数
常用函数无法满足日常需求,比如脱敏:去掉敏感数据
自定义函数包括三种:UDF、UDAF、UDTF
-
UDF:一进一出
-
UDAF:聚集函数,多进一出。如:Count/max/min
-
UDTF:一进多出,如 lateralview 侧视图 explore()
使用方式 :在HIVE 会话中 add 自定义函数的 jar 文件,然后创建 function 继而使用函数。
UDF 开发(常用)
1、UDF 函数可以直接应用于 select 语句,对查询结构做格式化处理后,再输出内容。
2、编写 UDF 函数的时候需要注意一下几点:
a)自定义 UDF 需要继承类 org.apache.hadoop.hive.ql.UDF。
b)需要实现 evaluate 函数,evaluate 函数支持重载。
源码:
package com.hive.udf; |
3、步骤
a)把程序打包放到目标机器上去;
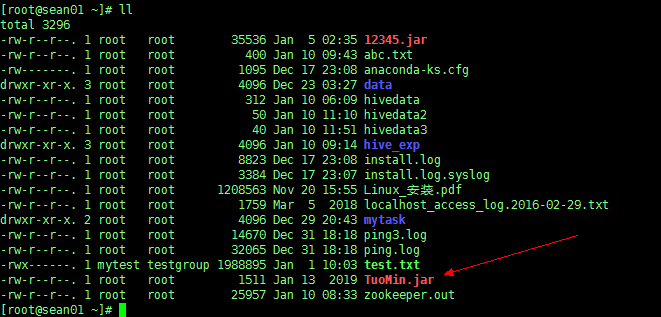
b)进入 hive 客户端,添加 jar 包:
因为 jar 包添加到环境变量中,所以不用的时候要删除
hive > add jar /root/TuoMin.jar; |
c)创建临时函数:
hive > create temporary function tuomin as 'com.hive.udf.TuoMin'; |
d)查询 HQL 语句:
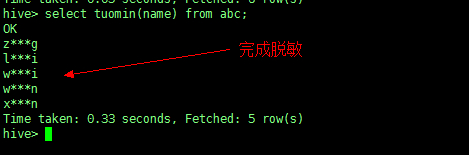
使用自定义函数 tuomin 来查询表 abc 的 name 字段
表 abc 原数据

进行脱敏
select tuomin(name) from abc; |
e)销毁临时函数:
hive > drop temporary function tuomin; |
UDAF 自定义集函数(不用)
多行进一行出,如 sum()、min(),用在 group by 时
1、必须继承org.apache.hadoop.hive.ql.exec.UDAF(函数类继承)
org.apache.hadoop.hive.ql.exec.UDAFEvaluator(内部类 Eval uator 实现 UDAFEvaluator 接口)
2、Evaluator 需要实现 init、iterate、terminatePartial、merge、t erminate 这几个函数
- init():类似于构造函数,用于 UDAF 的初始化
- iterate():接收传入的参数,并进行内部的轮转,返回 boolean
- terminatePartial():无参数,其为 iterate 函数轮转结束后,返回轮转数据,类似于 hadoop 的 Combinermerge(),用于接收 terminatePartial 的返回结果,进行数据 merge 操作,其返回类型为 boolean
- terminate():返回最终的聚集函数结果
UDTF (不常用)
一进多出,如 lateral view explode()
案例实战
基站掉话率
1、创建原始表
create table cell_monitor( |
2、结果表
create table cell_drop_monitor( |
3、加载原始数据
LOAD DATA LOCAL INPATH '/root/cdr_summ_imei_cell_info.csv' OVERWRITE INTO TABLE cell_monitor; |
4、找出掉线率最高的基站
from cell_monitor cm |
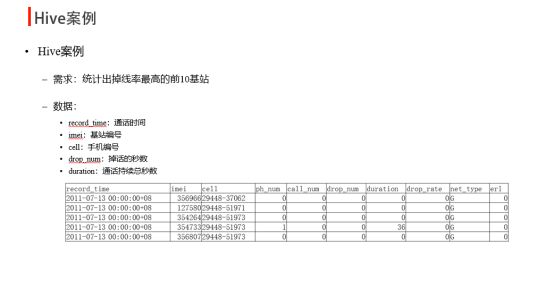
5、查询结果表
比如查询前十条数据
select * from cell_drop_monitor limit 10; |
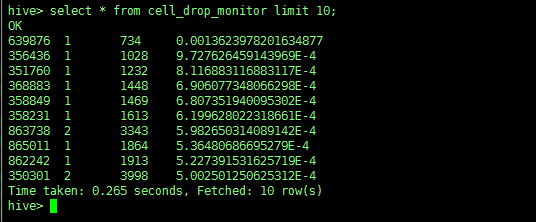
WC 单词统计
案例:做一个单词统计
例如:新建一个叫 wc 的文件

1、建表
create table docs(line string); #原表 |
2、加载原始数据
load data local inpath '/root/wc' into table docs; |
3、统计
from (select explode(split(line, ' ')) as word from docs) w |
4、查询结果
select * from wc; |
分桶
分桶表及应用场景
分桶表是对列值取哈希值求余的方式,将不同数据放到不同文件中存储。
对于hive中每一个表、分区都可以进一步进行分桶。由列的哈希值除以桶的个数来决定每条数据划分在哪个桶中。
适用场景:
数据抽样( sampling )、map-join
开启支持分桶
set hive.enforce.bucketing=true;
默认:false;设置为 true 之后,mr 运行时会根据bucket的个数自动分配 reduce task 个数。(用户也可以通过mapred.reduce.tasks 自己设置 reduce 任务个数,但分桶时不推荐使用)
注意:一次作业产生的桶(文件数量)和 reduce task 个数一致。
往分桶表中加载数据
insert into table bucket_table select columns from tbl; |
桶表 抽样查询
select * from bucket_table tablesample(bucket 1 out of 4 on columns); #抽样函数 |
tablesample 语法:
tablesample(bucket x out of y)
x:表示从哪个bucket开始抽取数据
y:必须为该表总bucket数的倍数或因子
1、创建普通表
例:
CREATE TABLE mm( id INT, name STRING, age INT) |
测试数据:
1,tom,11 |
在本地 root 下创建一个 hivedata4 的文件
2、创建分桶表
create table psnbucket( id int, name string, age int) |
3、加载数据到普通表
load data local inpath '/root/hivedata4' into table mm; |
4、插入数据到分桶表中
insert into table psnbucket select id, name, age from mm; |

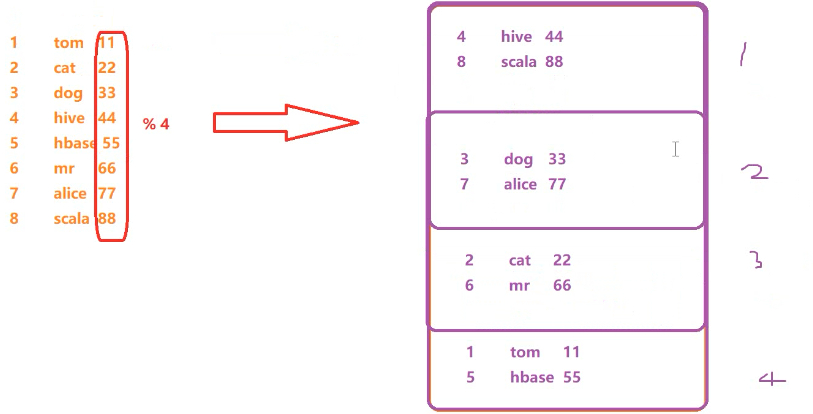
5、抽样
select id, name, age from psnbucket tablesample(bucket 1 out of 4 on age); |
从第一个桶开始抽一直到第四个
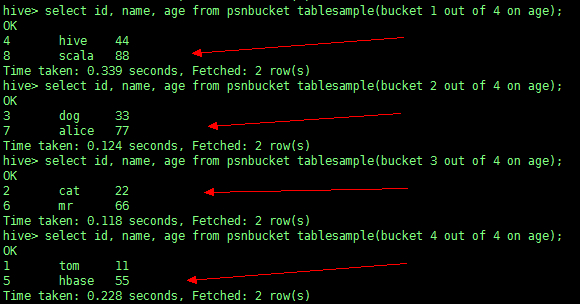
总结:我们互发现,在分桶抽样中,抽取数据会尽量分散去取
分析图:
Hive Lateral View(视图)
Lateral View 用于和 UDTF 函数(explode、split)结合来使用。
首先通过 UDTF 函数把一个语句拆分成多行,然后通过 Lateral View 将多行结果组合成一个支持别名的虚拟表,也就是合并为一个字段。
主要解决在select使用UDTF做查询过程中,查询只能包含单个UDTF,不能包含其他字段、以及多个UDTF的问题。
简单说:UDTF 先一进多出,Lateral View 拿到多条数据后多进一出。
语法:
lateral view udtf(expression) tableAlias as columnAlias (',' columnAlias) |
例:
统计人员表中共有多少种爱好、多少个城市?
数据来自表 abc

HQL语句:
select count(distinct(myCol1)), count(distinct(myCol2))) from abc |
显示结果:一共7种爱好、2个学习地址。

运行方式
**1、命令行方式 Cli:**控制台模式
-
与 hdfs 交互
执行 dfs 命令:例如 dfs -ls /
-
与 Linux 交互
! 开头:例如 !pwd
**2、脚本运行方式:**实际生产环境中使用最多
-
hive -e " SQL 语句 "
-
hive -e " " > aaa
-
hive -S -e “” > aaa -S意思是静默模式,不打印 log 日志信息
-
hive -f file(file里可以放很多SQL语句)
-
hive -i /home/my/hive-init.sql
-
hive > source file (在 hive cli 中运行)
3、JDBC 方式
hiveserver2
4、Web GUI 接口
hwi、hue等
Hive Web GUI接口
web界面安装:
1、下载源码包apache-hive-*-src.tar.gz
2、将hwi war包放在$HIVE_HOME/lib/
制作方法:将hwi/web/*里面所有的文件打成war包
cd apache-hive-1.2.1-src/hwi/web jar -cvf hive-hwi.war * |
3、复制tools.jar(在jdk的lib目录下)到$HIVE_HOME/lib下
4、修改hive-site.xml
<property> |
5、启动hwi服务(端口号9999)
hive --service hwi
6、浏览器通过以下链接来访问
Hive参数与变量
Hive当中的参数、变量
hive当中的参数、变量,都是以命名空间开头

通过${}方式进行引用,其中system、env下的变量必须以前缀开头。
Hive 参数设置方式
1、修改配置文件 ${HIVE_HOME}/conf/hive-site.xml
2、启动hive cli时,通过–hiveconf key=value的方式进行设置
例:hive --hiveconf hive.cli.print.header=true
3、进入cli之后,通过使用set命令设置
Hive set命令
在 hive CLI 控制台可以通过set对hive中的参数进行查询、设置。
-
set 设置:
set hive.cli.print.header=true;
-
set 查看:
set hive.cli.print.header
-
hive参数初始化配置
当前用户家目录下的.hiverc文件,如: ~/.hiverc
如果没有,可直接创建该文件,将需要设置的参数写到该文件中,hive启动运行时,会加载改文件中的配置。
-
hive历史操作命令集
~/.hivehistory
权限管理
权限类别
1、Storage Based Authorization in the Metastore Server基于存储的授权
可以对Metastore中的元数据进行保护,但是没有提供更加细粒度的访问控制(例如:列级别、行级别)。
2、Default Hive Authorization (Legacy Mode) hive默认授权
设计目的仅仅只是为了防止用户产生误操作,而不是防止恶意用户访问未经授权的数据。
3、SQL Standards Based Authorization in HiveServer2基于SQL标准的Hive授权
完全兼容SQL的授权模型,推荐使用该模式。
基于SQL标准Hive授权模型,除支持对于用户的授权认证,还支持角色role的授权认证,role可理解为是一组权限的集合,通过role为用户授权。一个用户可以具有一个或多个角色,默认包含俩种角色:public、admin
授权限制
1、启用当前认证方式之后,dfs, add, delete, compile, and reset等命令被禁用。
2、通过set命令设置hive configuration的方式被限制某些用户使用。
(可通过修改配置文件hive-site.xml中hive.security.authorization.sqlstd.confwhitelist进行配置)
3、添加、删除函数以及宏(批量规模)的操作,仅为具有admin的用户开放。
4、用户自定义函数(开放支持永久的自定义函数),可通过具有admin角色的用户创建,其他用户都可以使用。
5、Transform功能被禁用
在 hive 服务端修改配置文件 hive-site.xml 添加以下配置内容:
<property> |
服务端启动hiveserver2;客户端通过beeline进行连接
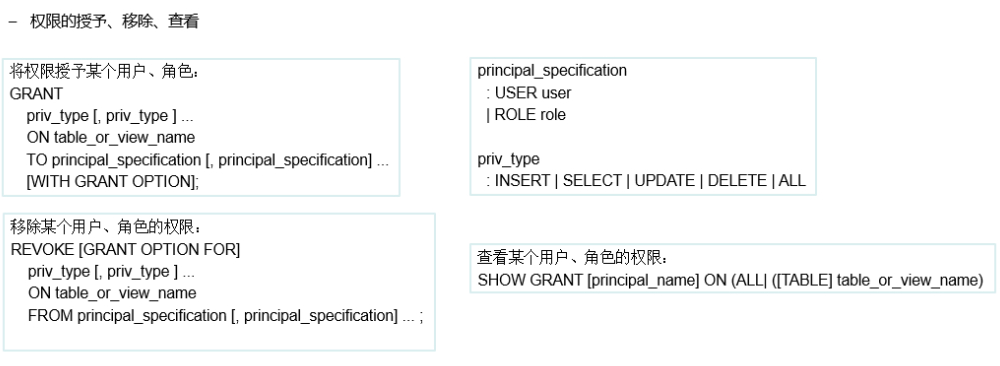
角色的添加、删除、查看、设置:
CREATE ROLE role_name; – 创建角色
DROP ROLE role_name; – 删除角色
SET ROLE (role_name|ALL|NONE); – 设置角色
SHOW CURRENT ROLES; – 查看当前具有的角色
SHOW ROLES; – 查看所有存在的角色

思考总结
1、Hive中的自定义函数的jar包放置
Hive自定义的函数jar包最好放置到分布式存储系统HDFS上,这样可以有效的防止当前节点服务器发生意外宕机,jar 包丢失。
 微信
微信 支付宝
支付宝



