
Hive中的优化策略
Hive优化核心思想
把 Hive SQL 当做 MapReduce 程序去优化。
注:以下 SQL 不会转为 MapReduce 来执行:
- select 仅查询本表字段
- where 仅对本表字段做条件过滤
几种常用的优化策略
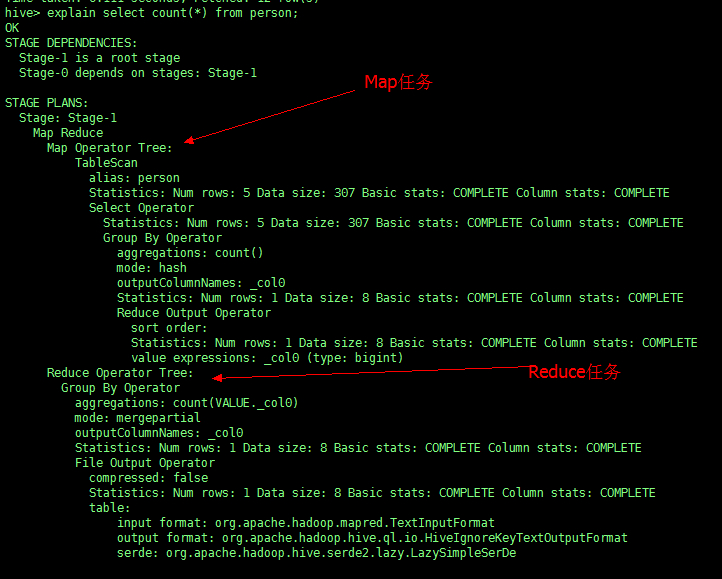
1、Explain 显示执行计划
在 sql 前添加关键字 explain,不会产生 MapReduce 任务,但会预先分析,程序大概需要执行的步骤。
例如:对表 person 进行统计
explain select count(*) from person; |
从表中我们可以看出,执行这个语句程序大概要运行的步骤。
2、Hive 运行方式
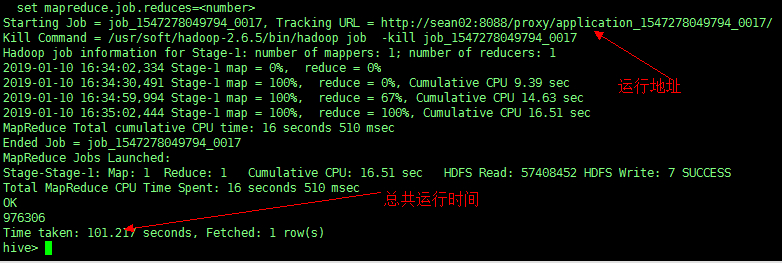
Hive 默认的运行方式为集群模式,当使用集群模式的时候程序会把任务提交到服务器去运行。
举例:对表 cell_monitor 进行统计查询操作
select count(*) from cell_monitor; |
从图中可以看出,MR任务被提交到服务器运行,时间为101秒,少量数据就提交到服务器,会严重消耗工作时间和增加服务器压力。
-
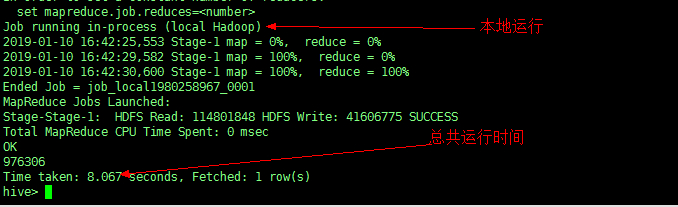
本地模式
开启本地模式
set hive.exec.mode.local.auto=true; #默认为false
再次进行查询
可以发现,运行时间大大缩短,同时节省资源,减轻服务器的压力。
-
集群模式
默认为 false
-
本地加载文件的最大值
hive.exec.mode.local.auto.inputbytes.max #默认值为128M(134217728)
注意:若加载文件的最大值大于该配置,仍会以集群方式来运行!
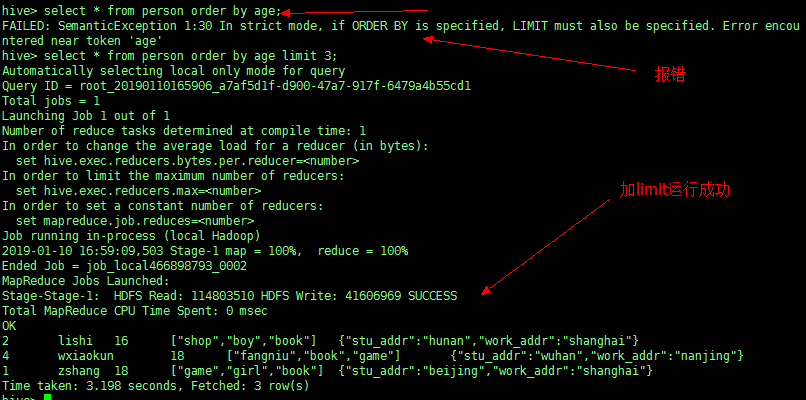
3、严格模式
-
通过设置以下参数开启严格模式[防止误操作]
set hive.mapred.mode=strict;
(默认为:nonstrict非严格模式) -
查询限制:
1、对分区表查询时,必须添加 where 对于分区字段的条件过滤;
2、order by 语句必须包含 limit 输出限制;
3、限制执行笛卡尔积的查询如不满足,则会报错!

4、Hive 排序
-
Order By - 对于查询结果做全排序,只允许有一个 reduce 处理
(当数据量较大时,应慎用。严格模式下,必须结合 limit 来使用,限制查询的数量)
-
Sort By - 对于单个 reduce 的数据进行排序(分布式处理)
-
Distribute By - 分区排序,经常和 Sort By 结合使用(对多个区进行排序)
-
Cluster By - 相当于 Sort By + Distribute By
(Cluster By 不能通过 asc、desc 的方式指定排序规则;可通过 distribute by column sort by column asc|desc 的方式)
5、Hive Join
Join 计算时,将小表(驱动表,数据量较少的表)放在 join 的左边。
Map Join:在 Map 端完成 Join
-
两种实现方式:
(1)SQL 方式,在 SQL 语句中添加 MapJoin 标记(mapjoin hint)
- 语法:
SELECT /*+ MAPJOIN(smallTable) */ smallTable.key, bigTable.value
FROM smallTable JOIN bigTable ON smallTable.key = bigTable.key;(2)开启自动的 MapJoin
通过修改以下配置启用自动的 mapjoin:
set hive.auto.convert.join = true;
(该参数为true时,Hive自动对左边的表统计量,如果是小表就加入内存,即对小表使用Map join)其他相关配置参数:
hive.mapjoin.smalltable.filesize;
(大表小表判断的阈值25MB左右,如果表的大小小于该值则会被加载到内存中运行)
hive.ignore.mapjoin.hint;
(默认值:true;是否忽略mapjoin hint 即map join标记)
hive.auto.convert.join.noconditionaltask;
(默认值:true;将普通的join转化为普通的map join时,是否将多个map join转化为一个map join)
hive.auto.convert.join.noconditionaltask.size;
(将多个map join转化为一个map join时,其表的最大值(默认10MB))注意:如果两个表都是小表,尽量把真正较小的表放到左边,提高性能。
6、Map-Side聚合
如 count() 等聚合函数
-
通过设置以下参数开启在Map端的聚合:
set hive.map.aggr=true;
-
相关配置参数:
hive.groupby.mapaggr.checkinterval;
map端group by执行聚合时处理的多少行数据(默认:100000)
hive.map.aggr.hash.min.reduction:
进行聚合的最小比例(预先对100000条数据做聚合,若 聚合的数据量/100000 的值小于该配置0.5,则不会聚合)
hive.map.aggr.hash.percentmemory:
map端聚合使用的内存的最大值(默认0.5)
hive.map.aggr.hash.force.flush.memory.threshold:
map端做聚合操作是hash表的最大可用内容,大于该值则会触发flush(默认0.9)
hive.groupby.skewindata
是否对Group By产生的数据倾斜做优化,默认为false
6、控制Hive中Map以及Reduce的数量
-
Map数量相关的参数
mapred.max.split.size
一个split的最大值,即每个map处理文件的最大值(默认256MB)
mapred.min.split.size.per.node
一个节点上split的最小值(默认1个)
mapred.min.split.size.per.rack
一个机架上split的最小值(默认1个) -
Reduce数量相关的参数
mapred.reduce.tasks
强制指定reduce任务的数量(默认-1)
hive.exec.reducers.bytes.per.reducer
每个reduce任务处理的数据量(默认256MB)
hive.exec.reducers.max
每个任务最大的reduce数(默认1009个)
[ Map数量 >= Reduce数量 ]
7、Hive - JVM重用
用来设置粗细粒度。
-
适用场景:
(1)小文件个数过多
(2)task 个数过多
-
通过下列参数来设置
set mapred.job.reuse.jvm.num.tasks=n;
(n为 task 插槽个数)**插槽个数:**是 JVM 中的一个计量单位。举个例子:我们常用的 window 系统,有32位和64位的,我们会发现32位的操作系统上不能运行64位的软件程序,但是64位操作系统上却可以运行32位的软件,这是因为64位就等于两个32位,我们把一个32位比作一个插槽,那64位就是2个插槽了。
-
缺点:
设置开启之后,task插槽会一直占用资源,不论是否有task运行,直到所有的 task 即整个 job 全部执行完成时,才会释放所有的task插槽资源!
 微信
微信 支付宝
支付宝



