
HBase性能优化
关于HBase的性能优化方法很多种,现在说说常用的几种,主要分为表设计、写表和读表操作。
HBase表的设计
Pre-Creating Regions(预分区)
默认情况下,在创建 HBase 表的时候会自动创建一个 region 分区,当导入数据的时候,所有的 HBase 客户端都向这一个 region 写数据,直到这个 region 足够大了才进行切分。如果在创建 HBase 的时候就进行预分区,则会减少当数据量猛增时由于 region split 带来的资源消耗,从而加快批量写入速度。这样当数据写入 HBase 时,会按照 region 分区情况,在集群内做数据的负载均衡。
HBase 表的预分区需要紧密结合业务场景来选择分区的 key 值,每个 region 都有一个 startKey 和一个 endKey 来表示该 region 存储的 rowKey 范围。
举例说明:
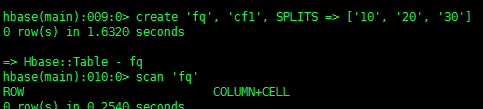
1、创建一个表 fq,列族为 cf1,被 splits 切成4个 region
方法一:
create 'fq', 'cf1', SPLITS => ['10', '20', '30'] |
方法二:
create 'fq', 'cf1', SPLITS => '/home/hbase/splitfile.txt' |
2、然后查看HBase web端,默认端口:60010(注意安装的节点位置)
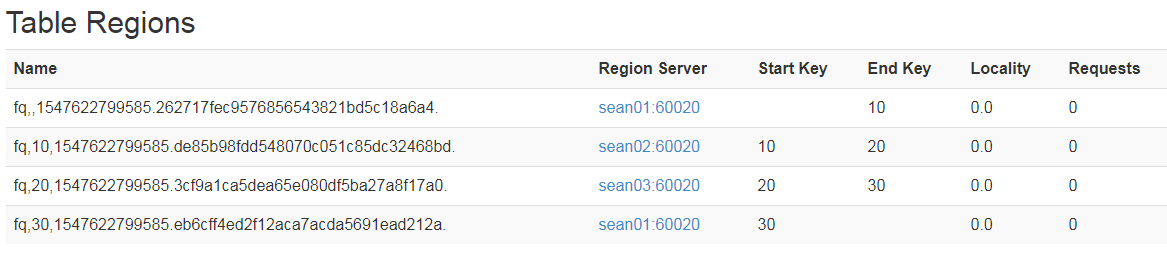
每个 region 的命名方式:[table],[region start key],[region id]
Row Key
HBase 中 row key 用来检索表中的记录,支持以下三种方式:
- 通过单个row key访问:即按照某个row key键值进行get操作。
- 通过row key的range进行scan:即通过设置startRowKey和endRowKey,在这个范围内进行扫描;过滤器。
- 全表扫描:即直接扫描整张表中所有行记录。
在 HBase 中,row key 可以是任意字符串,最大长度64KB,实际应用中一般为10~100bytes,存为 byte[] 字节数组,一般设计成定长的。
row key 是按照字典序存储,因此,设计 row key 时,要充分利用这个排序特点,将经常一起读取的数据存储到一块,将最近可能会被访问的数据放在一块。
举个例子:如果最近写入 HBase 表中的数据是最可能被访问的,可以考虑将时间戳作为 row key 的一部分,由于是字典序排序,所以可以使用 Long.MAX_VALUE - timestamp 作为 row key ,这样能保证新写入的数据在读取时可以被快速命中。
Rowkey 设计规则:
1、 定长 越小越好
2、 Rowkey 的设计是要根据实际业务来
3、 散列性
-
取反,如:001 002 100 200
-
Hash
Column Family(列族)
不要在一张表里定义太多的column family。
目前 Hbase 并不能很好的处理超过2~3个 column family 的表。因为某个 column family 在 flush 的时候,它邻近的 column family 也会因关联效应被触发 flush,最终导致系统产生更多的 I/O,从而降低运行效率。
In Memory(内存缓存的第三级别)
在BlockCache缓存里面,有三个级别的缓存数据,前两个先清空,In Memory是第三个级别最高,缓存腾出空间时一定不会清空第三个,会去清除一和二级别的数据。
创建表的时候,可以通过 HColumnDescriptor.setInMemory(true) 将表放到 RegionServer 的缓存中,保证在读取的时候被 cache 命中。
Max Version (最大版本)
创建表的时候,可以通过 HColumnDescriptor.setMaxVersions(int maxVersions) 设置表中数据的最大版本,如果只需要保存最新版本的数据,那么可以设置 setMaxVersions(1)。
Time To Live(生命周期)
创建表的时候,可以通过 HColumnDescriptor.setTimeToLive(int timeToLive) 设置表中数据的存储生命期,过期数据将自动被删除,例如如果只需要存储最近两天的数据,那么可以设置:setTimeToLive(2*24*60*60)。
Compact(合并) & Split(裂变)
在 HBase 中,数据在更新时首先写入 WAL 日志 (HLog) 和内存 (MemStore) 中,MemStore 中的数据是排序的,当 MemStore 累计到一定阈值时,就会创建一个新的 MemStore,并且将老的 MemStore 添加到 flush 队列,由单独的线程 flush 到磁盘上,成为一个 StoreFile。于此同时, 系统会在 zookeeper 中记录一个 redo point,表示这个时刻之前的变更已经持久化了**(minor compact)**。
StoreFile 是只读的,一旦创建后就不可以再修改。因此 Hbase 的更新其实是不断追加的操作。当一个 Store 中的StoreFile 数量达到一定的阈值后,就会进行一次合并 (major compact),将对同一个 key 的修改合并到一起,形成一个大的 StoreFile,当 StoreFile 的大小达到一定阈值后,又会对 StoreFile 进行分割 (split),等分为两个 StoreFile。
由于对表的更新是不断追加的,处理读请求时,需要访问 Store 中全部的 StoreFile 和 MemStore,将它们按照row key 进行合并,由于 StoreFile 和 MemStore 都是经过排序的,并且 StoreFile 带有内存中索引,通常合并过程还是比较快的。
实际应用中,可以考虑必要时手动进行 major compact,将同一个 row key 的修改进行合并形成一个大的 StoreFile。同时,可以将 StoreFile 设置大些,减少 split 的发生。
hbase 为了防止小文件(被刷到磁盘的 menstore)过多,以保证保证查询效率,hbase 需要在必要的时候将这些小的 store file 合并成相对较大的 store file,这个过程就称之为 compaction。
在 hbase 中,主要存在两种类型的compaction:minor compaction 和 major compaction。
minor compaction:
较小、很少文件的合并。
major compaction:
功能是将同一个 store 里所有的 store file 合并成一个,触发 major 。
major compaction 的可能条件有:
-
手动
major_compact 命令
majorCompact( ) API
-
自动
region server自动运行需要的相关参数:
hbase.hregion.major compaction 默认为24 小时(有浮动)。
把24改成0就可以关闭自动合并hbase.hregion.majorcompaction.jetter 默认值为 0.2 。
hbase.hregion.majorcompaction.jetter:浮动参数,防止region server在同一时间进行major compaction
hbase.hregion.majorcompaction:规定的值起到浮动的作用,避免多个 region 在同一时间合并争抢资源。假如两个参数都为默认值24和0.2,那么 major compact 最终使用的数值为:19.2~28.8 这个范围。
minor compaction 的运行机制要复杂一些,它由一下几个参数共同决定:
-
hbase.hstore.compaction.min:默认值为 3,表示一次 minor compaction 中最少选取3个 store file,minor compaction 才会启动。
-
hbase.hstore.compaction.max 默认值为10,表示一次 minor compaction 中最多选取10个 store file。
-
hbase.hstore.compaction.min.size 表示文件大小小于该值的 store file 一定会加入到 minor compaction 的 store file 中。
-
hbase.hstore.compaction.max.size 表示文件大小大于该值的 store file 一定会被 minor compaction 排除。
-
hbase.hstore.compaction.ratio 将 store file 按照文件年龄排序(older to younger),minor compaction 总是从 older store file 开始选择。
写表操作
多HTable并发写
创建多个 HTable 客户端用于写操作,提高写数据的吞吐量,一个例子:
static final Configuration conf = HBaseConfiguration.create(); |
此方式如果表过多,Java API 可能无法运行,因为实际上还是一个线程在跑,是个伪多线程。
HTable参数设置
Auto Flush
通过调用 HTable.setAutoFlush(false) 方法可以将 HTable 写客户端的自动 flush 关闭,这样可以批量写入数据到HBase,而不是有一条 put 就执行一次更新,只有当 put 填满客户端写缓存时,才实际向 HBase 服务端发起写请求。默认情况下 auto flush 是开启的。
Write Buffer
通过调用 HTable.setWriteBufferSize(writeBufferSize) 方法可以设置 HTable 客户端的写 buffer 大小,如果新设置的 buffer 小于当前写 buffer 中的数据时,buffer 将会被 flush 到服务端。其中,writeBufferSize 的单位是 byte 字节数,可以根据实际写入数据量的多少来设置该值。
WAL Flag
在 HBase 中,客户端向集群中的 RegionServer 提交数据时(Put/Delete操作),首先会先写 WAL(Write Ahead Log)日志(即HLog,一个RegionServer上的所有Region共享一个HLog),只有当 WAL 日志写成功后,再接着写 MemStore,然后客户端被通知提交数据成功;如果写 WAL 日志失败,客户端则被通知提交失败。这样做的好处是可以做到 RegionServer 宕机后的数据恢复。
因此,对于相对不太重要的数据,可以在 Put/Delete 操作时,通过调用 Put.setWriteToWAL(false) 或Delete.setWriteToWAL(false) 函数,放弃写 WAL 日志,从而提高数据写入的性能。
值得注意的是:谨慎选择关闭WAL日志,因为这样的话,一旦RegionServer宕机,Put/Delete的数据将会无法根据WAL日志进行恢复。
批量写
通过调用 HTable.put(Put) 方法可以将一个指定的 row key 记录写入 HBase,同样 HBase 提供了另一个方法:通过调用 HTable.put(List
多线程并发写
在客户端开启多个 HTable 写线程,每个写线程负责一个 HTable 对象的 flush 操作,这样结合定时 flush 和写 buffer(writeBufferSize),可以既保证在数据量小的时候,数据可以在较短时间内被 flush(如1秒内),同时又保证在数据量大的时候,写 buffer 一满就及时进行 flush。下面给个具体的例子:
for (int i = 0; i < threadN; i++) { |
这个方法跟”多HTable并发写“类似,也是一个伪多线程。
最终的方法我们还是要通过MR+HBase的整合来进行分布式的写操作。
MR+HBase
测试前先保证Hadoop集群和HBase已启动
以 word count 单词统计为例:
1、API 源码
Job 类:
public class WCJob { |
Mapper 类:
public class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable> { |
Reducer 类:
public class WCReducer extends TableReducer<Text, IntWritable, ImmutableBytesWritable>{ |
2、查看Eclipse打印结果
可看出,MR任务执行成功!
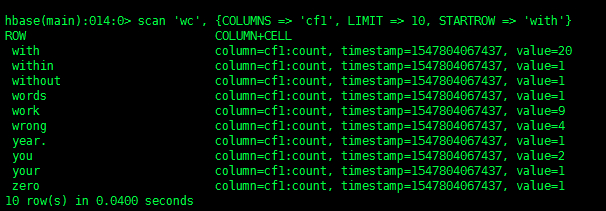
3、去HBase客户端查看
可以查看一下表数据(如果表数据过大,慎用 scan 查询全表),但是可以用RowKey来控制范围
scan 'wc', {COLUMNS => 'cf1', LIMIT => 10, STARTROW => 'with'} |
或者可以直接使用 get 查看一下 “with” 这个单词有多少个。
get 'wc','with','cf1:count' #查询表wc中RowKey为‘with’,列族为‘cf1’的‘count’字段的值 |

读表操作
多HTable并发读
与 “多HTable并发写” 类似。创建多个 HTable 客户端用于读操作,提高读数据的吞吐量,一个例子:
static final Configuration conf = HBaseConfiguration.create(); |
HTable参数设置
Scanner Caching
hbase.client.scanner.caching 配置项可以设置 HBase scanner 一次从服务端抓取的数据条数,默认情况下一次一条。通过将其设置成一个合理的值,可以减少 scan 过程中 next() 的时间开销,代价是 scanner 需要通过客户端的内存来维持这些被 cache 的行记录。
有三个地方可以进行配置:
1)在 HBase 的 conf 配置文件中进行配置;
2)通过调用 HTable.setScannerCaching(int scannerCaching) 进行配置;
3)通过调用 Scan.setCaching(int caching) 进行配置。
三者的优先级越来越高。
Scan Attribute Selection
scan 时指定需要的 Column Family,可以减少网络传输数据量,否则默认 scan 操作会返回整行所有 Column Family 的数据。
scan.addColumn("cf1".getBytes(), "name".getBytes()); |
Close ResultScanner
通过 scan 取完数据后,记得要关闭 ResultScanner,否则 RegionServer 可能会出现问题(对应的Server资源无法释放)。
批量读
与 “批量写类似”。通过调用 HTable.get(Get) 方法可以根据一个指定的 row key 获取一行记录,同样 HBase 提供了另一个方法:通过调用 HTable.get(List
多线程并发读
“多线程并发读” 类似。
在客户端开启多个 HTable 读线程,每个读线程负责通过 HTable 对象进行 get 操作。
缓存查询结果
对于频繁查询 HBase 的应用场景,可以考虑在应用程序中做缓存,当有新的查询请求时,首先在缓存中查找,如果存在则直接返回,不再查询 HBase;否则对 HBase 发起读请求查询,然后在应用程序中将查询结果缓存起来。至于缓存的替换策略,可以考虑 LRU 等常用的策略。
BlockCache
HBase 上 Regionserver 的内存分为两个部分,一部分作为 Memstore,主要用来写;另外一部分作为 BlockCache,主要用于读。
写请求会先写入 Memstore,Regionserver 会给每个 region 提供一个 Memstore,当 Memstore 满64MB以后,会启动 flush 刷新到磁盘。当 Memstore 的总大小超过限制时(heapsize*hbase.regionserver.global. memstore .upperLimit*0.9),会强行启动 flush 进程,从最大的 Memstore 开始flush 直到低于限制。
heapsize:RegionServer的内存大小。
hbase.regionserver.global.memstore.upperLimit:表示RegionServer进程block进行flush触发条件,默认配置:0.4
第一次读请求先到 Memstore 中查数据,查不到就到 BlockCache 中查,再查不到就会到磁盘上读,并把读的结果放入 BlockCache。由于 BlockCache 采用的是LRU策略,因此 BlockCache 达到上限 (heapsize*hfile.block. cache.size*0.85)后,会启动淘汰机制,淘汰掉最老的一批数据。
hfile.block.cache.size:BlockCache的大小
一个 Regionserver 上有一个 BlockCache 和N个 Memstore,它们的大小之和必须小于 heapsize*0.8,否则 HBase 不能启动。默认 BlockCache = heapsize*0.8*0.2,而 Memstore = heapsize*0.8*0.4。对于注重读响应时间的系统,可以将 BlockCache 设大些,比如设置 BlockCache=0.4,Memstore=0.39,以加大缓存的命中率。
HBase与DBMS比较
DBMS:关系型数据库。
查询数据不灵活:
1、不能使用column之间过滤查询
2、不支持全文索引。使用ElasticSearch(solr)和HBase整合完成全文索引。
- 使用RM批量读取HBase中的数据,在ES中建立索引(no store)保存rowkey的值。
- 根据关键词从索引中搜索到rowkey(分页查询)。
- 根据rowkey从HBase查询到所有数据。
HBase与ES的整合:
举个例子:假如在HBase中有一个表,表的rowkey为name,然后还有age、class两个字段,里面有上百万上千万的数据,实现一个功能找出名字中包含国强的,普通方法只能全表扫描,效率太低。
我们使用ES来建立索引,把name这个值放到ES的document中,检索的时候就可以先去ES中去找,因为ES使用的是倒排索引,分词建索引了,所以速度很快。找到之后假如总共100个,然后拿着这些name再去HBase中查询所有数据。
另外一种,假如HBase中的rowkey不是name,是其他的比如 id 什么的,这个时候 ES 的document除了要保存name之外,还要保存一个rowkey的字段,这样根据name就能找到对应的rowkey,检索到想要查找的所有数据。
总结一点,在进行 HBase 与 ES 的整合时,ES 的 document 中一定要包含 HBase 的rowkey,否则无法关联到 ES。
 微信
微信 支付宝
支付宝



