
Sqoop架构
Sqoop 简介
Sqoop是将关系数据库(oracle、mysql、postgresql等)数据与hadoop数据进行转换的工具。
版本:(两个版本完全不兼容,sqoop1使用最多)
- sqoop1:1.4.x
- sqoop2:1.99.x
同类产品:
- DataX:阿里顶级数据交换工具
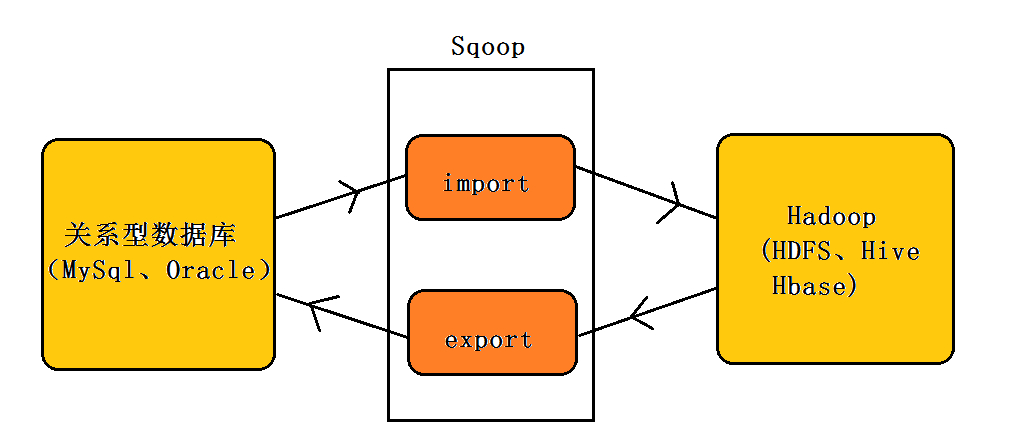
Sqoop 架构
sqoop 架构非常简单,是 hadoop 生态系统的架构最简单的框架,它主要由三个部分组成:Sqoop client、HDFS/HBase/Hive、Database。
sqoop1 由 client 端直接接入 hadoop,任务通过解析生成对应的 maprecue 执行。

Sqoop 导入
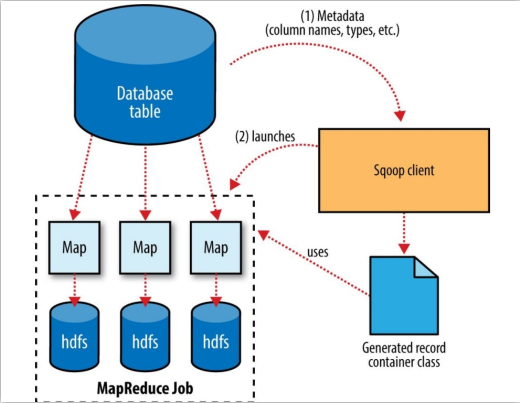
Sqoop 导出
Sqoop 安装使用
Sqoop 安装
1、下载解压 Sqoop
可以到apache基金sqoop官网 http://hive.apache.org/,选择镜像下载地址:http://mirror.bit.edu.cn/apache/sqoop/下载一个稳定版本。

**2、配置环境变量 **
vim ~/.bash_profile #这里配置局部环境变量 |
source ~/.bash_profile #刷新环境变量 |
3、添加数据库驱动包
cp mysql-connector-java-5.1.10.jar /sqoop-install-path/lib |
4、重命名配置文件
mv sqoop-env-template.sh sqoop-env.sh |
5、修改配置 configure-sqoop
在 sqoop 安装包的 bin 目录下
注释掉未安装服务相关内容;
例如(HCatalog、Accumulo):
## Moved to be a runtime check in sqoop. |
6、测试
sqoop version #测试版本号 |
注意:我这里报了一个错
Error: /usr/soft/sqoop-1.4.6.bin/bin/…/…/hadoop does not exist!
Please set $HADOOP_COMMON_HOME to the root of your Hadoop installation.

根据错误提示缺少的 hadoop 安装路径配置,需修改 sqoop 配置文件。
网上给出的办法是:
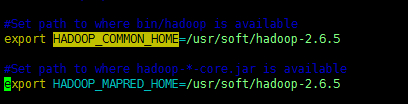
进入sqoop下的conf目录编辑 sqoop-env.sh 文件,给 HADOOP_COMMON_HOME 和 HADOOP_MAPRED_HOME 添加 hadoop 安装路径,注意去掉#号 [ # 是注释 ]
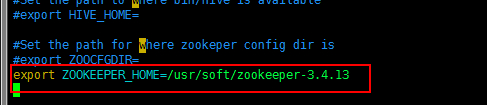
重新检测,发现还有警告,需要添加 ZOOKEEPER_HOME,填上 Zookeeper 的安装路径。

重新回到 sqoop-env.sh 文件中,添加如下一行:
再次检测,完美!

7、连接数据库
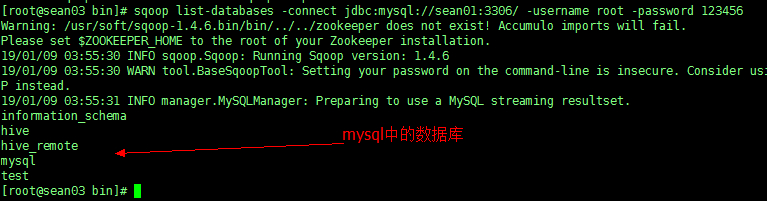
sqoop list-databases -connect jdbc:mysql://sean01:3306/ -username root -password 123456 |
连接之前记得一定要先启动 mysql 数据库
Sqoop 参数
Sqoop 连接参数

Sqoop 导入参数

Sqoop 导出参数

Sqoop 操作
将关系型数据库中的数据导入到 HDFS/Hive/Hbase。
mysql导入到HDFS/Hive/HBase
导入到 HDFS
1、先准备数据,在 mysql 中建表 stu

2、在 sqoop 上执行语句
sqoop import --connect jdbc:mysql://localhost:3306/sqoop --username root --password 123456 --table stu -m 1 -target-dir hdfs://Xss/mysqoop #指明集群名称和导入的路径 |

从日志打印中可以得知只运行了 Map,不改变结果。
3、在HDFS Web端上查看
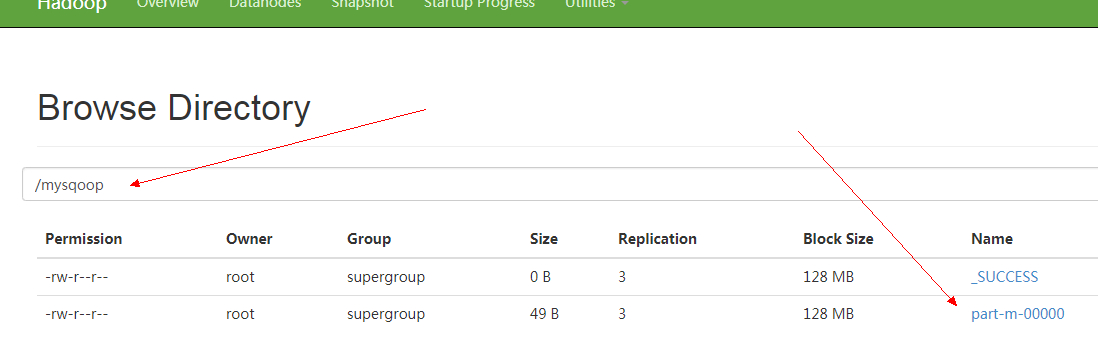
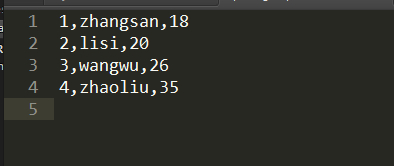
4、下载打开得到数据
导入到 Hive
1、先启动 Hive
这里注意:Hive不同的配置模式启动也不同,但要保证一点,Hive的客户端必须跟Sqoop在一个节点上,否则报错!
我这里3个节点用的是远程分开模式,所以需要分别启动服务端 sean02 和客户端 sean03


2、在 sqoop 上执行语句
sqoop import --connect jdbc:mysql://sean01:3306/sqoop --username root --password 123456 --table stu -m 1 --hive-import |
这里最终导入 Hive 的地址,我们在远程一体模式中配置文件中已经指定好了路径,在服务端的Hive安装包的 conf目录下的 hive-site.xml 文件中
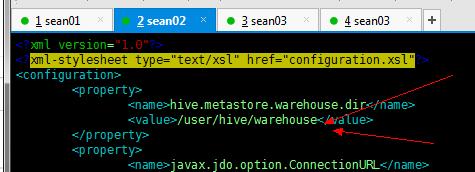
执行完毕我们来HDFS(因为Hive的数据也是存储到HDFS中)查看
3、HDFS Web端查看Hive数据
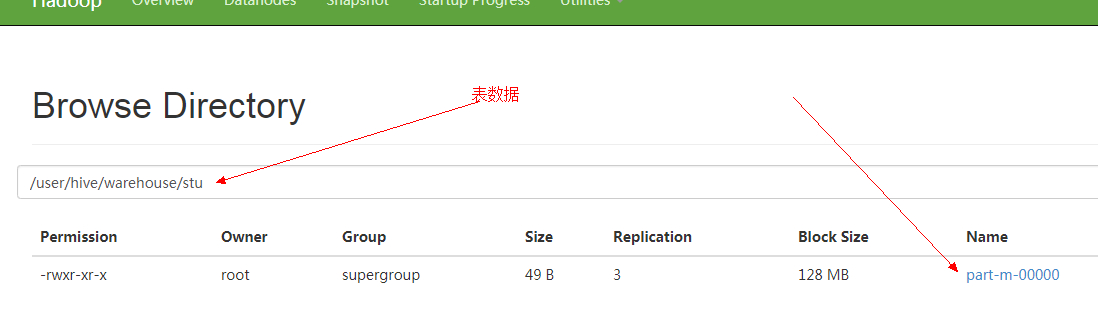
4、下载查看
HDFS/Hive/HBase导出到mysql
1、清空 mysql 的表数据
清空表 stu 为导出做准备。
2、在 Sqoop 上执行语句
#从HDFS中导出 |
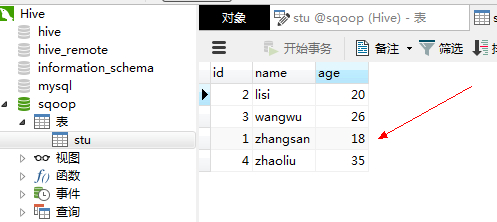
3、查看 Navivat中的mysql
可以看出,数据已经成功导出
4、从Hive中导出同理
#从Hive中导出 |
注意:这里的\001是Hive默认的分隔符,属于不可见字符,这个字符在vi里是^A
我们可以在 vim 中查看一下
hdfs dfs -cat /user/hive/warehouse/stu/part-m-00000 |

会发现分隔符并不可见
但是我们下载下载使用 vim 查看呢
hdfs dfs -get /user/hive/warehouse/stu/part-m-00000 |
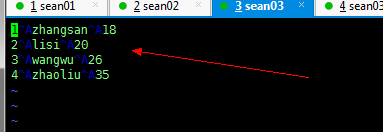
这个字符在 vi 里是 ^A
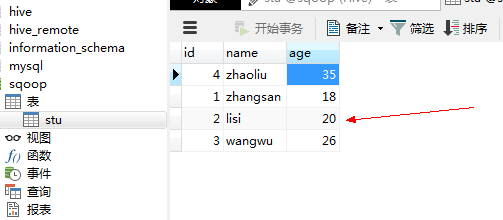
5、再次清空mysql中的stu表,执行语句从Hive导出,查看Navcat
表stu数据再次回来,表示从 Hive 中完美导出
 微信
微信 支付宝
支付宝



