
Flume框架
Flume简介
Flume 是一个分布式、可扩展、可靠、高可用的海量日志有效聚合及移动的框架。
它通常用于log数据,支持在系统中定制各类数据发送方,用于收集数据。它具有可靠性和容错可调机制和许多故障转移和恢复机制。
Flume通常用于收集日志数据,但不限于收集日志,还可以收集其他的数据信息。
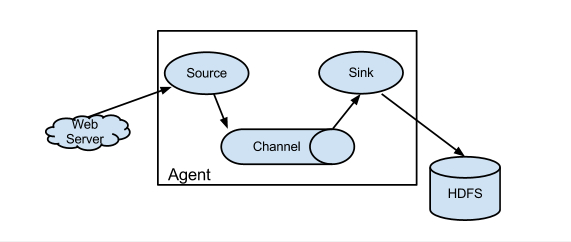
Flume组织架构
Flume的版本分为 OG 组织架构和 NG 组织架构,但原来的Flume OG到现在的Flume NG,进行了架构重构,并且现在NG版本完全不兼容原来的OG版本。
OG组织架构
Flume OG:Flume original generation 即 Flume 0.9.x版本,它采用三层架构,分别为agent,Collector和Master,所有的 agent 和 Collector 由 master 统一管理,master允许有多个(使用Zookeeper进行管理和负载均衡),避免单点故障问题。
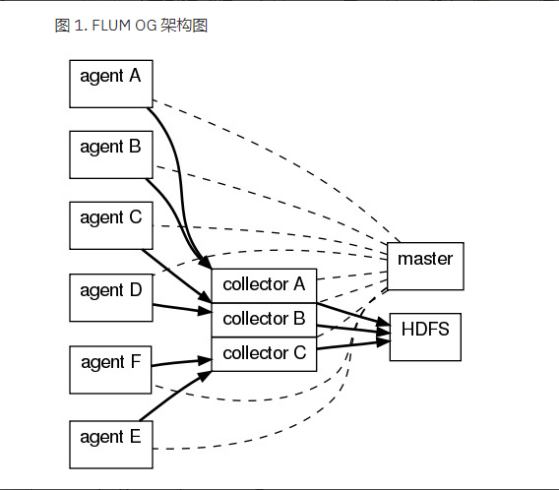
NG组织架构
Flume NG:Flume next generation ,即Flume 1.x版本,只有 agent,由Source、Channel和 Sink组成。
Flume 经过架构重构后,Flume NG更像是一个轻量的小工具,非常简单,容易适应各种方式日志收集,并支持 failover和负载均衡。

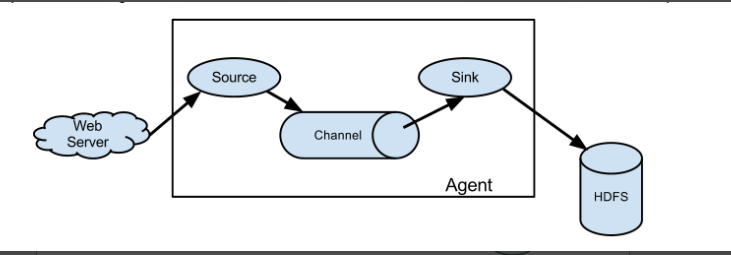
Agent
Agent 由source、channel、sink三大组件组成,如图:
1、Source
- Source负责接收event或通过特殊机制产生event,并将events批量的放到一个或多个Channel。
- Source包含event驱动和轮询两种类型。
- Source 有不同的类型,接受不同的数据格式。
1)与系统集成的Source:netcat、syslog。
2)自动生成事件的Source:exec
3)用于Agent和Agent之间的通信的IPC Source:avro、thrift。 - Source必须至少和一个Channel关联。
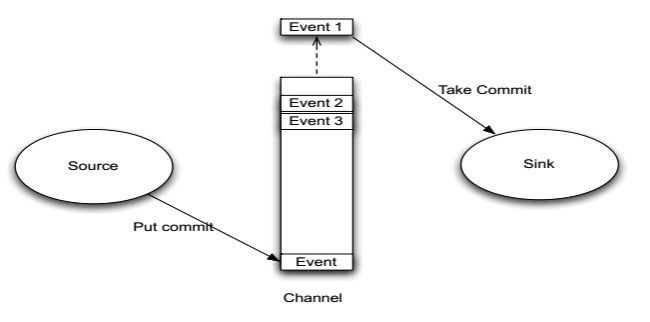
2、Channel
- Channel位于Source和Sink之间,用于缓存进来的event。
- 当Sink成功的将event发送到下一跳的Channel或最终目的地,event才Channel中移除。
- 不同的Channel提供的持久化水平也是不一样的:
1)Memory Channel:volatile。
2)File Channel:基于WAL实现。
3)JDBC Channel:基于嵌入Database实现。 - Channel支持事物,提供较弱的顺序保证。
- Channel可以和任何数量的Source和Sink工作。
3、Sink
- Sink负责将event传输到下一跳或最终目的,成功完成后将event从Channel移除。
- 有不同类型的Sink:
1)存储event到最终目的的终端Sink。比如Logger,HDFS,HBase,Hive。
2)自动消耗的Sink。比如:Kafka。
3)用于Agent间通信的IPC sink:Avro。 - Sink必须作用于一个确切的Channel。
4、Agent之Channel与Sink关系图
Flume的特性
1、数据可靠性(内部实现)
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。
FFlume提供了三种级别的可靠性保障,所有的数据以event为单位传输,从强到弱依次分别为:
**end-to-end:**收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。
**Store on failure:**这也是scribe采用的策略,当数据接收方crash(崩溃)时,将数据写到本地,待恢复后,继续发送。
**Best effort:**数据发送到接收方后,不会进行确认。
2、自身可扩展性
Flume采用了三层架构,分别为agent,collector和master,每一层均可以水平扩展。所有agent和 collector由master统一管理,使得系统容易监控和维护。master允许有多个(使用ZooKeeper进行管理和负载均衡),避免单点故障问题。【1.0自身agent实现扩展】
3、功能可扩展性
用户可以根据需要添加自己的agent。
Flume自带了很多组件,包括各种agent(file,syslog,HDFS等)。
Flume安装及使用
Flume的安装
1、下载flume安装包并解压。
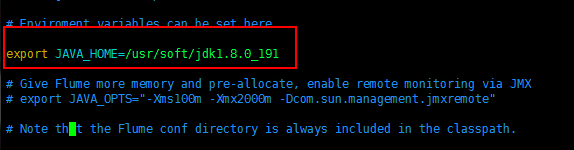
2、修改 flume-env.sh 配置文件,主要是 JAVA_HOME 设置
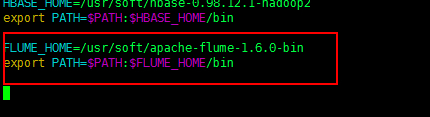
3、配置环境变量[可选局部环境变量设置]
4、将当前节点的环境变量及 flume 安装包发送给其他节点
scp -r ~/.bash_profile sean02:/usr/soft/ |
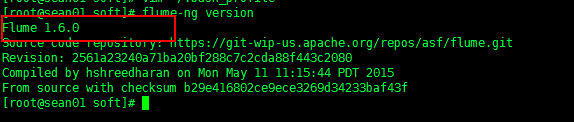
5、验证是否安装成功 flume-ng version
Flume的使用操作
网络传输格式
**exec:**查看追踪。Unix 等操作系统执行命令行 ,如:tail cat
**netcat:**来监听一个指定端口,并将接收到的数据的每一行转换为一个event事件。
**avro:**是序列化的一种,实现了RPC(Remote Procedure Call),RPC是一种远程调用协议 。监听AVRO端口来接受来自外部AVRO客户端的事件流。
配置 flume
详细参数可以参照官网,1.4X以上的版本可以使用1.8的文档。
http://flume.apache.org/releases/content/1.8.0/FlumeUserGuide.html
一、netcat --> logger
1、安装telnet
telnet 命令通常用来远程登录。telnet程序是基于TELNET协议的远程登录客户端程序。Telnet协议是TCP/IP协议族中的一员,是Internet远程登陆服务的标准协议和主要方式。它为用户提供了在本地计算机上完成远程主机工作的能力。在终端使用者的电脑上使用telnet程序,用它连接到服务器。终端使用者可以在telnet程序中输入命令,这些命令会在服务器上运行,就像直接在服务器的控制台上输入一样。可以在本地就能控制服务器。要开始一个 telnet会话,必须输入用户名和密码来登录服务器。
yum list telnet* #查看telnet相关的安装包 |
2、配置参数:
# example.conf: A single-node Flume configuration |
示意图:
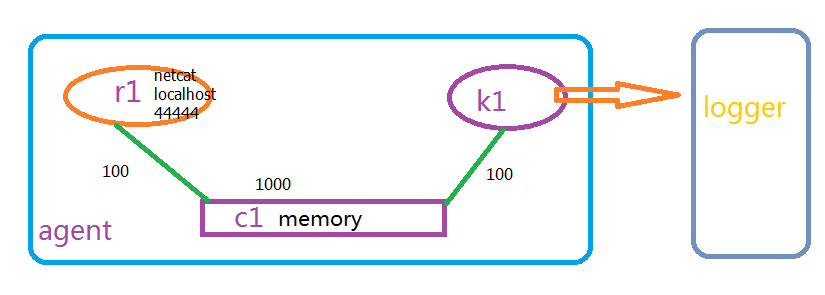
3、运行flume
(1)在 root目录下新建文件夹 flume,新建配置文件 netcat_logger,参数如上。
(2)运行命令:
使用绝对路径,可以在任意路径启动 |
使用相对路径,只能在 flume当前路径下启动 |
启动成功!
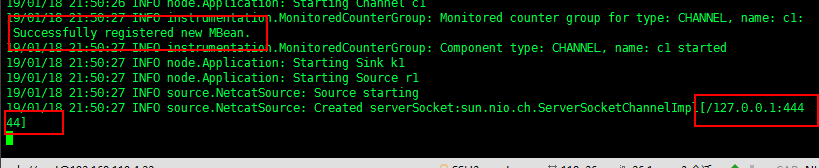
(3)在当前节点另开窗口输入命令
telnet localhost 44444 |
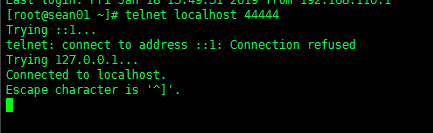
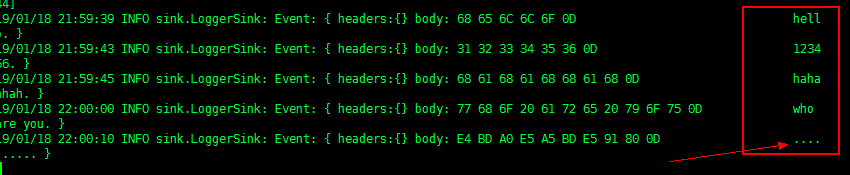
(4)在telnet中source端输入任意数据,然后去sink端去查看数据
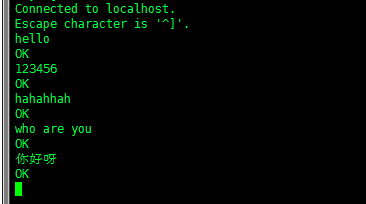
注意:中文不显示
二、exec --> looger
1、配置参数:
example.conf: A single-node Flume configuration |
示意图

2、运行flume
(1)在文件夹 flume,新建配置文件 exec_logger,参数如上。
(2)运行命令:
flume-ng agent --conf-file exec_logger --name a1 -Dflume.root.logger=INFO,console |
(3)启动成功后在当前节点另开窗口输入命令
echo hello world >> flume.log #将“hello world”追加到flume.log文件中 |
(4)去sink端查看数据

三、avro --> logger
1、配置参数
a1.sources=r1 |
示意图

2、运行flume
(1)在文件夹 flume,新建配置文件 avro_logger,参数如上。
(2)运行命令:
flume-ng agent --conf-file avro_logger --name a1 -Dflume.root.logger=INFO,console |
(3)启动成功后在其他节点输入命令
#其他flume节点执行: |
例如:在 sean02 节点 root 下有个 test.txt 文件,发送到sean01,查看sink端
sean02上的test.txt 文件
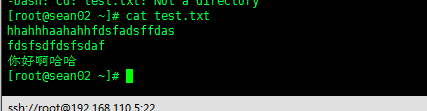
在sean01上成功拿到

四、netcat --> hdfs
1、配置参数
a1 which ones we want to activate. |
示意图
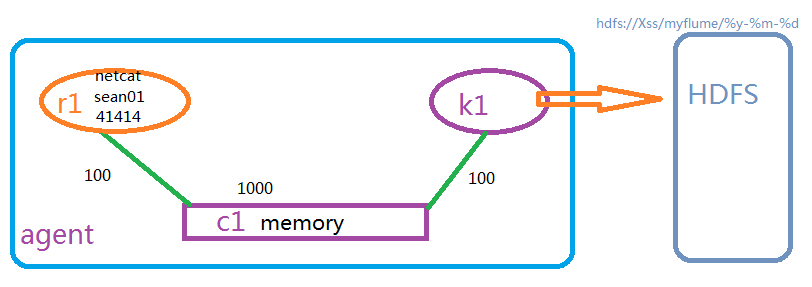
2、运行flume
(1)在文件夹 flume,新建配置文件 netcat_hdfs,参数如上。
(2)当前 sink 端运行命令:
flume-ng agent --conf-file netcat_hdfs --name a1 -Dflume.root.logger=INFO,console |
(3)启动成功后在当前节点输入命令,进入sink端
telnet sean01 41414 |
成功进入后,在source端输入数据。
然后去HDFS web端看目录 myflume/%y-%m-%d 下的数据
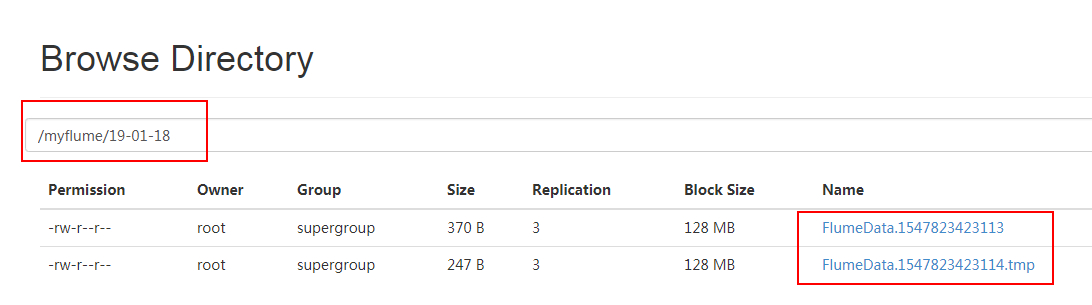
说明成功获取到!
注意:这样上传到会形成很多小文件,对HDFS来说很不友好,这就需要我们去调整一下参数,扩大等待时间或者每个文件的大小,尽量以大文件的形式来存储到HDFS中。
相关参数官网上都有详细介绍:
http://flume.apache.org/releases/content/1.8.0/FlumeUserGuide.html
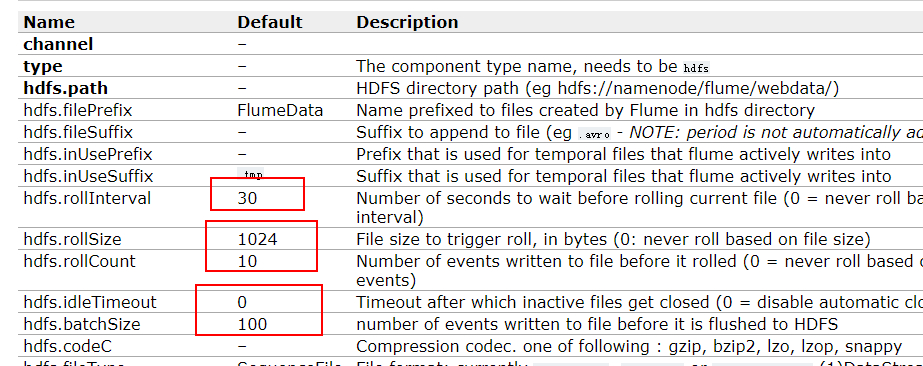
**hdfs.rollInterval:**默认等待30秒数据落地到磁盘。如果不想基于时间的话,设为0。
**hdfs.rollSize:**默认1024个字节落地到磁盘。
**hdfs. rollCount:**默认统计10个事件就写入磁盘
**hdfs.idleTimeout:**操作时间
**hdfs.batchSize:**默认每一批100个事件写入 HDFS 中
 微信
微信 支付宝
支付宝



