
Elasticsearch分布式搜索引擎
ES简介
Elasticsearch 是一个基于 Lucene 的实时的分布式搜索和分析 引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠, 快速,安装使用方便。基于 RESTful 接口。
Lucene 与 ES 关系
1、Lucene 只是一个库。想要使用它,你必须使用 Java 来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene 非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
2、Elasticsearch 也使用 Java 开发并使用 Lucene 作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API 来隐藏 Lucene 的复杂性,从而让全文搜索变得简单。
Elasticsearch 与 Solr 对比
1、ElasticSearch查询速度更快。
2、Elasticsearch是分布式的。不需要其他组件,分发是实时的。
3、Elasticsearch 完全支持 Apache Lucene 的接近实时的搜索,处理多租户(multitenancy)不需要特殊配置,而 Solr 则需要更多的高级设置。
4、Elasticsearch 采用 Gateway 的概念,使得备份更加简单。
Elasticsearch 与关系型数据库对比
ES 与关系型数据库非常类似:

REST 简介
REST 全称是 Resource Representational State Transfer,通俗来讲就是:资源在网络中以某种表现形式进行状态转移。分解开来:
- Resource:资源,即数据。比如 news,friends 等;
- Representational:某种表现形式,比如用 JSON,XML,JPEG 等;
- State Transfer:状态变化。通过 HTTP 动词实现。
它一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件。
它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
 ****
****
Rest 操作
REST 的操作分为以下几种:
- GET:获取对象的当前状态;
- PUT:改变对象的状态;
- POST:创建对象;
- DELETE:删除对象;
- HEAD:获取头信息。
ES 内置的 REST 接口

CURL 命令
常见参数
-
-X:指定http请求的方法
-
-HEAD/GET/POST/PUT/DELETE -d :指定要传输的数据
常用操作
1、索引库的创建与删除
- 创建索引库
url -XPUT http://192.168.110.4:9200/xss/ #xss为创建索引库的名称 |
- 删除索引库
curl -XDELETE http://192.168.110.4:9200/xss/ |
2、创建Document
- -d 后跟 Json 格式
- pretty:把返回结果转换成便于识别的 Json 格式
curl -XPUT http://192.168.110.4:9200/xss/employee/1?pretty -d '{ |
3、更新Document
- 局部更新,
可以添加新字段或者更新已有字段(必须使用 POST)
curl -XPOST http://192.168.110.4:9200/xss/employee/1/_update -d ' |
- 全局更新(使用
PUT,与创建Document相同)
curl -XPUT http://192.168.110.4:9200/xss/employee/1 -d '{"city":"beijing","car":"BMW"}' |
注意:PUT 和 POST 都是新增,修改。PUT必须指定ID,所以PUT一般数据更新 。POST 可以指定ID,也可以不指定 做新增比较好。
4、普通查询索引
- 根据ID查询
curl -XGET http://192.168.110.4:9200/xss/employee/1?pretty |
- curl后添加 -i 参数,能得到反馈头文件
curl -i XGET http://192.168.110.4:9200/xss/employee/1?pretty |
- 检索文档中的一部分,只需要显示指定字段
curl -XGET http://192.168.110.4:9200/xss/employee/1?_source=name,age |
- 查询所有
curl -XGET http://192.168.110.4:9200/xss/employee/_search?pretty |
- 根据条件进行查询
curl -XGET http://192.168.110.4:9200/xss/employee/_search?q=last_name:smith |
5、DSL 查询
DSL:Domain Specific Language
– 领域特定语言
# 对单个field发起查询:match |
– 举例:查询 first_name=bin 的,并且年龄不在 20 岁到 30 岁之间的
curl -XGET http://192.168.110.4:9200/xss/employee/_search -d ' |
6、删除索引
curl -XDELETE http://192.168.110.4:9200/xss/employee/1?pretty |
- 如果文档存在,es 会返回 200 ok 的状态码,found 属性值为 true,_version 属性的值+1
- found 属性值为 false,但是_version 属性的值依然会+1,这个就是内部管理的一部分,它保证了我们在多个节点间的不同操作的顺序都被正确标记了。
注意:删除一个文档也不会立即生效,它只是被标记成已删除。 Elasticsearch 将会在你之后添加更多索引的时候才会在后台进行删除内容的清理。
ES安装部署
下载解压ES包
所有集群节点都要安装。
修改配置
config/elasticsearch.yml 文件
a)Cluster.name: my_cluster (同一集群要一样) |
启动
ES_HOME/bin/elasticsearch |
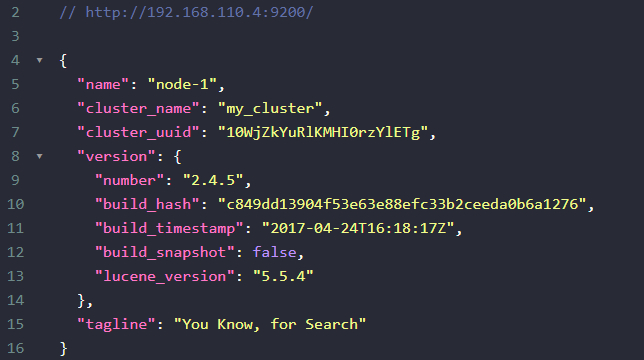
访问(默认端口9200)
http://192.168.110.4:9200 |
ElasticSearch插件安装
head
通过 rest 请求,未免太过麻烦,而且也不够人性化。head能后帮助我们快捷查看 es 的运行状态以及数据的可视化工具。
1、安装:在线安装
bin目录下执行./plugin install mobz/elasticsearch-head |
2、启动elasticsearch
bin目录下执行./elasticsearch |
3、访问(_plugin/head目录)
注意:访问的节点必须安装head,只需要安装一台即可。
http://192.168.110.6:9200/_plugin/head |

Kibana
Kibana 是一个基于浏览器页面的ES前端展示工具,是为ES提供日志分析的web接口,可用它对日志进行高效的搜索、可视化、分析等操作。
1、解压安装
2、修改配置文件 config/kibana.yml的elasticsearch.url 属性,elasticsearch.url 指定任意节点都可以,他会自动进行内部广播。
Marvel
Marvel 插件可以帮助使用者监控 elasticsearch 的运行状态,不过这个插件需要 license。安装完license后可以安装 marvel 的 agent,agent 会收集elasticsearch 的运行状态。
1、安装license和marvel-agent(3台都装)
bin目录下执行./plugin install license |
2、安装Marvel(在kibana机器上安装)
Kibana_home/bin/kibana plugin --install elasticsearch/marvel/late #远程安装,速度慢 |
3、重启ES,启动Kibana
bin/elasticsearch |
4、页面访问(默认端口5601)
注意:与head插件相同,访问的节点必须安装Kibana,只需要安装一台即可。
http://192.168.110.6:5601 |

分词器集成
这里使用的是 IK 中文分词器。
1、下载IK分词器
https://github.com/medcl/elasticsearch-analysis-ik |
2、安装步骤
-
在 elasticsearch 的 plugins目录下新建ik目录,将分词器包拷贝到ik目录下
-
通过unzip命令解压缩(第一次需要yum安装unzip)
unzip elasticsearch-analysis-ik-1.8.0.zip |
- 修改文件权限为普通用户(否则无法启动ES)
3、重启集群
注意:3台机器都要安装(因为添加数据和查询数据都要分词)
4、使用操作
- 创建索引库
curl -XPUT http://192.168.110.4:9200/ik |
- 设置 mapping
curl -XPOST http://192.168.110.4:9200/ik/ikType/_mapping -d'{ |
- 插入数据
curl -XPOST http://192.168.110.4:9200/ik/ikType/1 -d' |
- 查询
curl -XGET http://192.168.110.4:9200/ik/ikType/_search?pretty -d'{ |

Elasticsearch 核心概念
cluster
代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。
es 的一个重要概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看 es 集群,在逻辑上是个整体,你与任何一 个节点的通信和与整个 es 集群通信是等价的。
主节点的职责是负责管理集群状态,包括管理分片的状态和副本的状态,以及节点的发现和删除。
-
只需要在同一个网段之内启动多个 es 节点,就可以自动组成一个集群。
-
默认情况下 es 会自动发现同一网段内的节点,自动组成集群。
-
集群状态查看
– http://192.168.110.4:9200/_cluster/health?pretty |
shards
代表索引分片,es 可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。
-
分片的数量只能在索引创建前指定,并且索引创建后不能更改。
-
分片的数量可以在创建索引库的时候指定。
curl -XPUT '192.168.110.4:9200/test1/' -d'{"settings":{"number_of_shards":3}}' |
- 默认是一个索引库有 5 个分片:number_of_shards: 5
replicas
代表索引副本,es 可以给索引设置副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高 es 的查询效率,es 会自动对搜索请求进行负载均衡。
- 可以在创建索引库的时候指定。
curl -XPUT '192.168.110.4:9200/test2/' -d'{"settings":{"number_of_replicas":2}}' |
- 默认是一个分片有 1 个副本 (总共有两片):number_of_replicas: 1
recovery
代表数据恢复或叫数据重新分布,es 在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
gateway
代表 es 索引的持久化存储方式,es 默认是先把索引存放到内存中,当内存满了时再持久化到硬盘。当这个 es 集群关闭再重新启动时就会从 gateway 中读取索引数据。es 支持多种类型的 gateway,有本地文件系统(默认),分布式文件系统,Hadoop 的 HDFS 和 amazon 的s3 云存储服务。
如果需要将数据落地到 hadoop 的 hdfs 需要先安装插件 elasticsearch/elasticsearch-hadoop。
discovery.zen
代表 es 的自动发现节点机制,es 是一个基于 p2p 的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
**思考:**如果是不同网段的节点如何组成 es 集群
- 禁用自动发现机制
discovery.zen.ping.multicast.enabled: false |
- 设置新节点被启动时能够发现的主节点列表
discovery.zen.ping.unicast.hosts: [“192.168.110.4", " 192.168.110.5", " 192.168.110.6"] |
Transport
代表 es 内部节点或集群与客户端的交互方式,默认内部是使用 tcp 协议进行交互,同时它支持 http 协议(json 格式)、thrift、servlet、 memcached、zeroMQ 等的传输协议(通过插件方式集成)。
ES 中的 settings 和 mappings
settings:修改索引库默认配置
- 例如:分片数量,副本数量
curl -XGET http://192.168.110.4:9200/xss/_settings?pretty #获取当前分片及副本数量 |
curl -XPUT http://192.168.110.4:9200/helloword/ -d '{ |
Mapping:就是对索引库中索引的字段名称及其数据类型进行定义
类似于关系数据库中表建立时要定义字段名及其数据类型那样,不过 es 的 mapping 比数据库灵活很多,它可以动态添加字段。一般不需要指定 mapping 都可以,因为 es 会自动根据数据格式定义它的类型,如果你需要对某些字段添加特殊属性(如:定义使用其它分词器、是否分词、是否存储等),就必须手动添加 mapping。
- 查询索引库的 mapping 信息
curl -XGET http://192.168.110.4:9200/xss/employee/_mapping?pretty |
- mappings 修改字段相关属性
例如:字段类型,使用哪种分词工具
Elasticsearch 的 java API
1、通过 TransportClient 这个接口,我们可以不启动节点就可以和es 集群进行通信, 它需要指定 es 集群中其中一台或多台机的 ip 地址和端口。
TransportClient client = new TransportClient() |
如果需要使用其他名称的集群(默认是 elasticsearch),需要如下设置:
Settings settings = ImmutableSettings.settingsBuilder() |
TransportClientclient = new TransportClient(settings) |
2、通过 TransportClient 这个接口,自动嗅探整个集群的状态,es 会自动把集群中其它机器的 ip 地址 加到客户端中。
Settings settings = ImmutableSettings.settingsBuilder().p |
TransportClient client = new TransportClient(settings) |
- 索引 index(四种 json,map,bean,es helpers)
IndexResponse response = client.prepareIndex(“shsxt", "em |
- 查询 get
GetResponse response = client.prepareGet(“shsxt", "emp", |
-
更新 update
-
更新或者插入 upsert
-
删除 delete
DeleteResponse response = client.prepareDelete(“shsxt", "e |
- 总数 count
long count = client.prepareCount(“shsxt").execute().get(). |
3、批量操作 bulk
- 查询 search(SearchType)

Elasticsearch 的查询
ES的搜索类型(四种):
1、query and fetch(速度最快,返回 N 倍数据量)
向索引的所有分片(shard)都发出查询请求,各分片返回的时候把元素文档(document)和计算后的排名信息一起返回。这种搜索方式是最快的。因为相比下面的几种搜索方式,这种查询方法只需要去shard 查询一次。但各个 shard 返回的结果的数量之和可能是用户要求的 size 的 n 倍。
2、query then fetch(默认的搜索方式)
如果你搜索时,没有指定搜索方式,就是使用的这种搜索方式。这种搜索方式,大概分两个步骤,第一步,先向所有的 shard 发出请求,各分片只返回排序和排名相关的信息(注意,不包括文档 document),然后按照各分片返回的分数进行重新排序和排名,取前 size个文档。然后进行第二步,去相关的 shard 取 document。这种方式返回的 document 与用户要求的 size 是相等的。
3、DFS query and fetch(更精确控制搜索打分)
这种方式比第一种方式多了一个初始化散发(initial scatter)步骤,有这一步可以更精确控制搜索打分和排名。
4、DFS query then fetch (最慢)
初始化散发其实就是在进行真正的查询之前,先把各个分片的词频率和文档频率收集一下,然后进行词搜索的时候,各分片依据全局的词频率和文档频率进行搜索和排名。显然如果使用 DFS_QUERY_THEN_FETCH 这种查询方式,效率是最低的,因为一个搜索,可能要请求3 次分片。但使用 DFS 方法,搜索精度应该是最高的。
总结:
从性能考虑 QUERY_AND_FETCH 是最快的, DFS_QUERY_THEN_FETCH 是最慢的。从搜索的准确度来说,DFS 要比非 DFS 的准确度更高。
查询:
query – builder.setQuery(QueryBuilders.matchQuery("name", "test")) |
分页:
from/size – builder.setFrom(0).setSize(1) |
排序:
sort – builder.addSort("age", SortOrder.DESC) |
过滤:
filter – builder.setPostFilter(QueryBuilders.rangeQuery("age").from(1).to(19)) |
**高亮:**highlight
统计:
facet(已废弃)使用 aggregations 替代 |
Elasticsearch 的分页
与 SQL 使用 LIMIT 来控制单“页”数量类似,Elasticsearch 使用的是 from 以及 size 两个参数:
-
size:每次返回多少个结果,默认值为 10
-
from:从哪条结果开始,默认值为 0
假设每页显示 5 条结果,那么 1 至 3 页的请求就是:
- GET /_search?size=5
- GET /_search?size=5&from=5
- GET /_search?size=5&from=10
**注意:**不要一次请求过多或者页码过大的结果,这么会对服务器造成很大的压力。因为它们会在返回前排序。一个请求会经过多个分片。每个分片都会生成自己的排序结果。然后再进行集中整理,以确保最终结果的正确性。
**timed_out:**告诉了我们查询是否超时。
curl -XGET http://localhost:9200/_search?timeout=10ms #es会在10ms之内返回查询内容 |
**注意:**timeout 并不会终止查询,它只是会在你指定的时间内返回当时已经查询到的数据,然后关闭连接。在后台,其他的查询可能会依旧继续, 尽管查询结果已经被返回了。
Elasticsearch 分片查询
**默认是 randomize across shards:**随机选取,表示随机的从分片中取数据。
**_local:**指查询操作会优先在本地节点有的分片中查询,没有的话再在其它节点查询。
**_primary:**指查询只在主分片中查询。
**_primary_first:**指查询会先在主分片中查询,如果主分片找不到(挂了), 就会在副本中查询。
**_only_node:**指在指定 id 的节点里面进行查询,如果该节点只有查询索引的部分分片,就只在这部分分片中查找,所以查询结果可能不完整。如 _only_node:123 在节点 id 为 123 的节点中查询。
**_prefer_node:nodeid:**优先在指定的节点上执行查询。
**_shards:0, 1, 2, 3, 4:**查询指定分片的数据。
Elasticsearch 中脑裂问题
所谓脑裂问题(类似于精神分裂),就是同一个集群中的不同节点,对于集群的状态有了不一样的理解。
**discovery.zen.minimum_master_nodes:**用于控制选举行为发生的最小集群节点数量。推荐设为大于1 的数值, 因为只有在 2 个以上节点的集群中,主节点才是有意义的。
正常情况下,集群中的所有的节点,应该对集群中 master 的选择是一致的,这样获得的状态信息也应该是一致的,不一致的状态信息,说明不同的节点对 maste 节点的选择出现了异常——也就是所谓的脑裂问题。这样的脑裂状态直接让节点失去了集群的正确状态,导致集群不能正常工作。
Elasticsearch 中脑裂产生的原因:
-
网络:由于是内网通信,网络通信问题造成某些节点认为 master 死掉,而另选 master 的可能性较小。
-
节点负载:由于 master 节点与 data 节点都是混合在一起的,所以当工作节点的负载较大时,导致对应的 ES 实例停止响应, 而这台服务器如果正充当着 master 节点的身份,那么一部分 节点就会认为这个 master 节点失效了,故重新选举新的节点, 这时就出现了脑裂;同时由于 data 节点上 ES 进程占用的内存较大,较大规模的内存回收操作也能造成 ES 进程失去响应。
Elasticsearch 中脑裂的解决方案:
- 主节点
node.master: true |
- 从节点
node.master: false |
- 所有节点
discovery.zen.ping.multicast.enabled: false #关闭自动自动广播 |
Elasticsearch 的优化
关于 ElasticSearch 的优化详见:[关于ElasticSearch的优化方案][https://www.seanxia.cn/大数据/53bfabca.html]
 微信
微信 支付宝
支付宝



