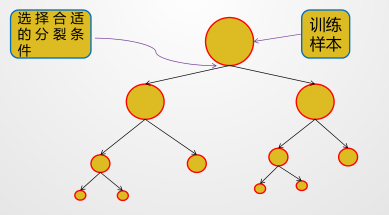
objectClassificationDecisionTree{ val conf = newSparkConf() conf.setAppName("analysItem") conf.setMaster("local[3]") val sc = newSparkContext(conf)
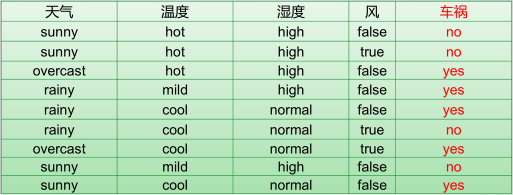
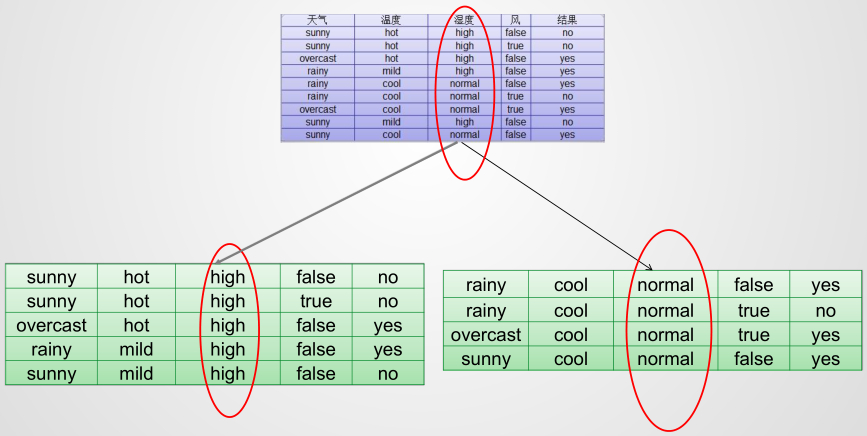
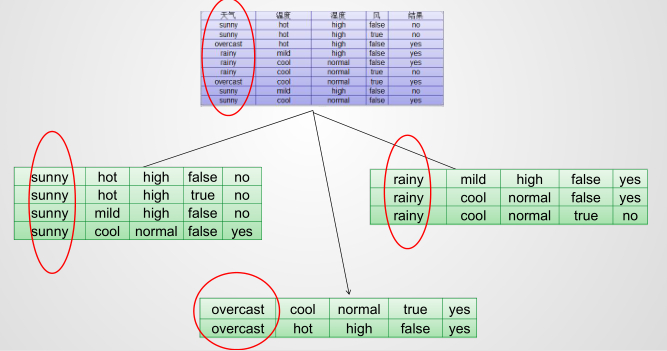
defmain(args: Array[String]): Unit = { val data = MLUtils.loadLibSVMFile(sc, "汽车数据样本.txt") // Split the data into training and test sets (30% held out for testing) val splits = data.randomSplit(Array(0.7, 0.3)) val (trainingData, testData) = (splits(0), splits(1)) //指明类别 val numClasses = 2 //指定离散变量,未指明的都当作连续变量处理 //1,2,3,4维度进来就变成了0,1,2,3 //这里天气维度有3类,但是要指明4,这里是个坑,后面以此类推 val categoricalFeaturesInfo = Map[Int, Int](0 -> 4, 1 -> 4, 2 -> 3, 3 -> 3) //设定评判标准 val impurity = "entropy" //树的最大深度,太深运算量大也没有必要 剪枝 val maxDepth = 3 //设置离散化程度,连续数据需要离散化,分成32个区间,默认其实就是32,分割的区间保证数量差不多 这个参数也可以进行剪枝 val maxBins =10 //生成模型 val model: DecisionTreeModel = DecisionTree.trainClassifier(trainingData, numClasses, categoricalFeaturesInfo, impurity, maxDepth, maxBins) //测试
val labelAndPreds: RDD[(Double, Double)] = testData.map { point => val prediction = model.predict(point.features) (point.label, prediction) } val testErr = labelAndPreds.filter(r => r._1 != r._2).count().toDouble / testData.count() println("Test Error = " + testErr) println("Learned classification tree model:\n" + model.toDebugString)




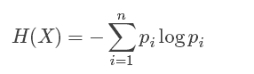
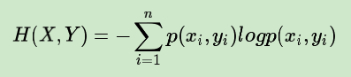
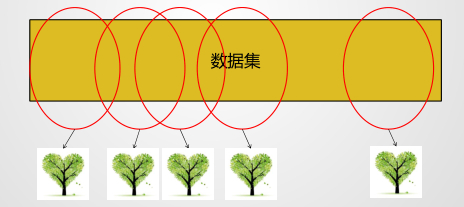
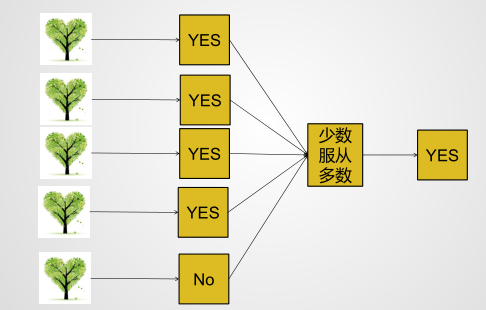

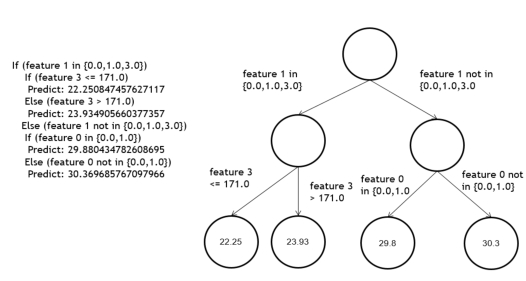
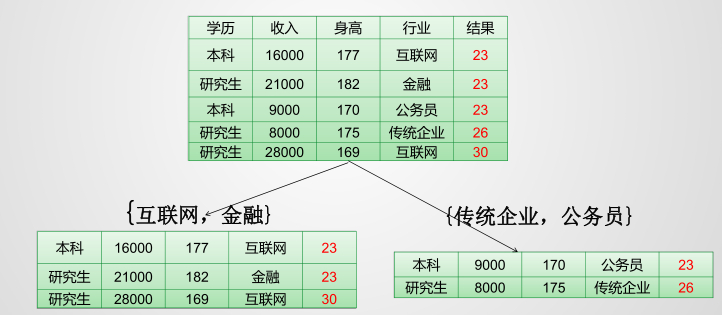
 微信
微信 支付宝
支付宝


